Teaching Drones to Understand Their Own Motion
A novel framework uses geometry-driven camera motion cues to improve how drones perceive and reason through video, boosting motion-awareness without expensive retraining.
TL;DR: A new framework helps drones interpret their own camera motion, bridging a critical gap in how video-language models understand movement. Using a synthetic dataset and lightweight prompting techniques, this approach significantly boosts motion-awareness without requiring expensive retraining.
Giving Drones a Sense of Motion
Drones are great at seeing the world, but how well do they truly understand their own movement while navigating it? This research dives into the subtle but important problem of camera motion awareness in video-language models (VideoLLMs). Researchers developed a method to teach models to recognize how the movement of a drone’s camera interacts with the scene it captures—essential for smarter navigation, improved scene understanding, and better decision-making in complex environments.
What’s Broken? Why It Needed Fixing
Current video-language models can describe what’s happening in a scene, but they’re largely blind to how the camera itself moves. That's a problem for drones, where the camera’s motion often reflects the vehicle’s own movement. Without understanding camera motion, models can:
- Misinterpret scenes (e.g., mistaking zooming in for an object moving closer).
- Struggle with spatial awareness.
- Fail during tasks like dynamic navigation or cinematic filming.
Retraining entire models to account for these issues is impractical due to cost, time, and computational constraints. There’s been no lightweight, efficient way to inject this kind of understanding—until now.
How It Works: Geometry Meets Deep Learning
This framework has three core components: benchmarking, diagnosis, and injection. Here's how it breaks down:
- Benchmarking: The authors created
CameraMotionDataset, a synthetic dataset with explicit labels for camera motion (e.g., panning, tilting, zooming). Using this, they builtCameraMotionVQA, a video question-answering benchmark to test how well existing VideoLLMs handle motion understanding. - Diagnosis: Experiments showed that most models fail to understand camera motion because motion cues get lost in the deeper layers of their visual encoders.
- Injection: Instead of retraining models, they extracted motion cues using frozen 3D foundation models (like
VGGT) and passed these cues through a lightweight temporal classifier to identify motion primitives. These inferred primitives were then injected into the VideoLLMs during inference as structured prompts.
Here’s the pipeline:
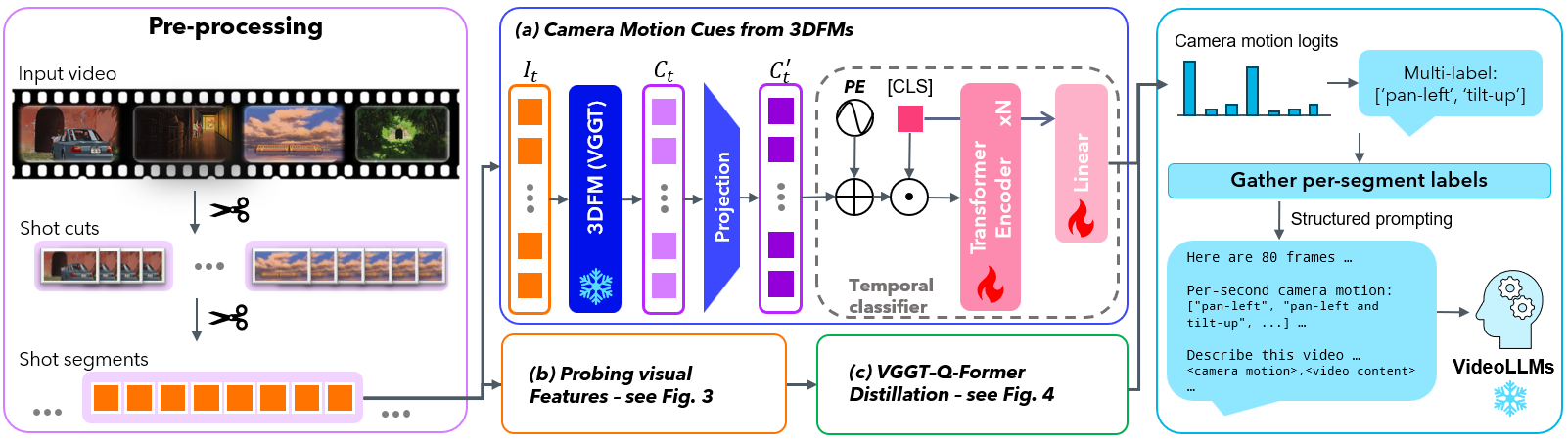
Caption: The framework extracts camera motion cues, classifies them, and injects this understanding into downstream tasks without modifying the underlying VideoLLMs.
Dataset Construction
To build CameraMotionDataset, videos were labeled with motion primitives (like “dolly,” “pan,” or “zoom”), balancing the dataset across classes for better learning. The pipeline ensures high-quality data for benchmarking.
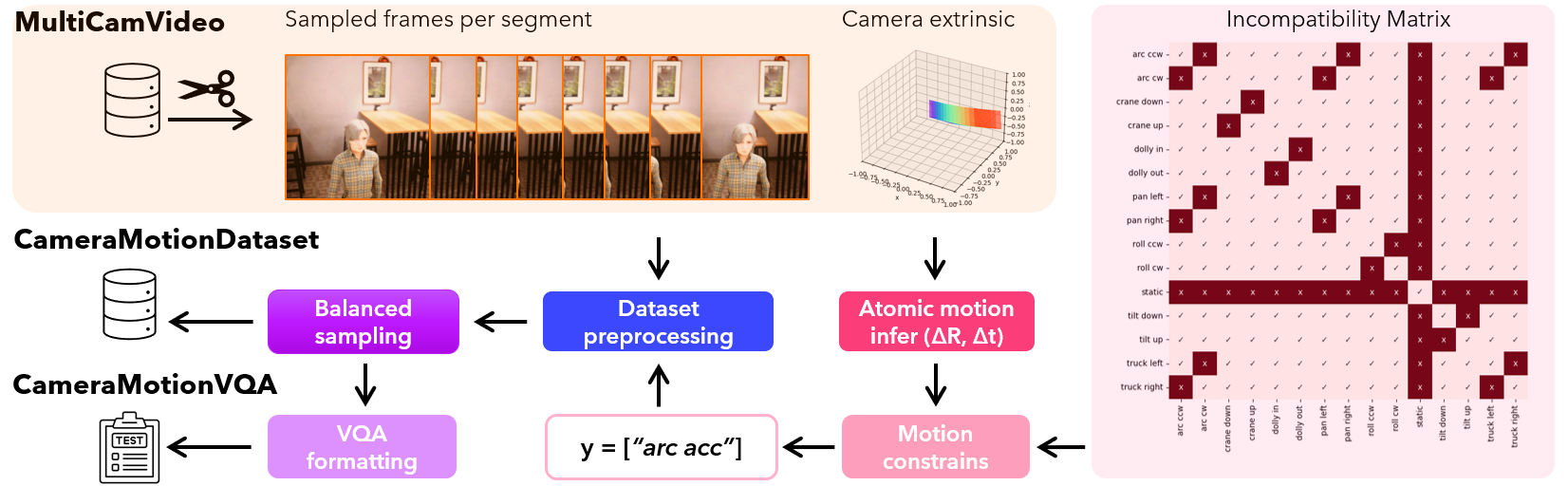
Caption: Steps for creating CameraMotionDataset and CameraMotionVQA benchmarks.
Where Do Models Fail?
A key discovery: motion-relevant cues degrade as data flows through the deeper layers of vision encoders like transformers. This explains why models struggle with fine-grained motion recognition.
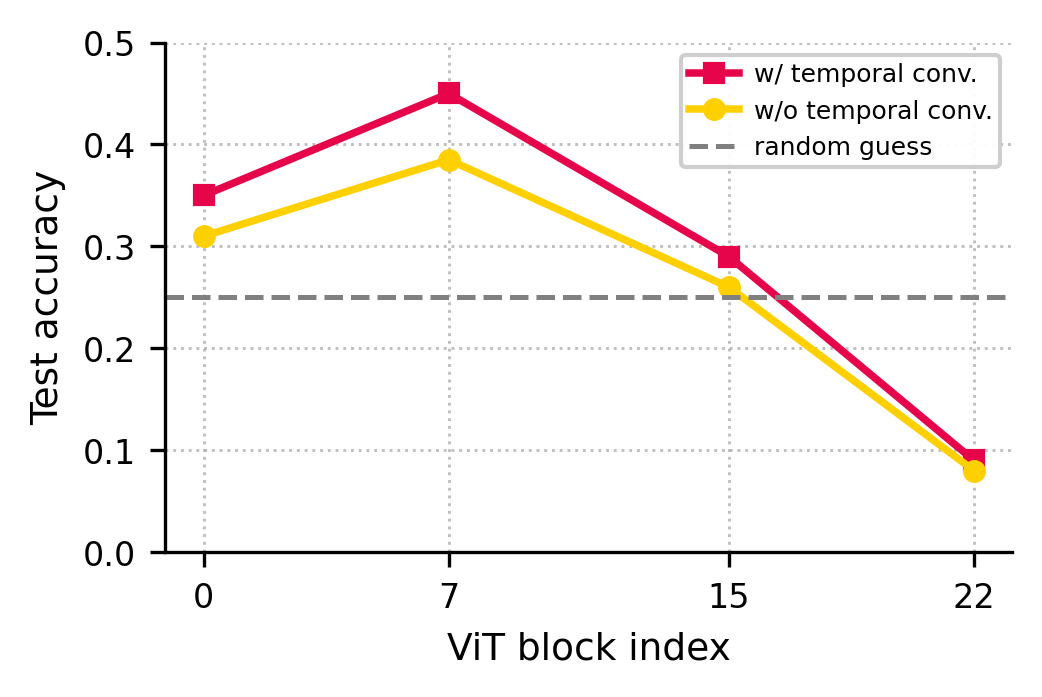
Caption: Motion-related features are strongest in shallow layers but weaken in deeper layers of vision encoders.
The Results: How Well Does It Work?
The approach improved camera motion understanding significantly without altering the base models. Key metrics include:
- Camera-motion recognition accuracy: Models saw substantial boosts in identifying motion primitives.
- Better video reasoning: VideoLLMs produced richer, more spatially accurate descriptions when motion cues were injected.
Take this example:

Caption: Structured motion prompts enable more precise, camera-aware descriptions compared to baseline outputs.
Why It Matters for Drones
Drones with this capability can:
- Navigate smarter: By understanding how their movement affects the scene, drones can avoid misjudgments during tasks like obstacle avoidance or docking.
- Film better: Cinematic drones could reason about framing and transitions, producing professional-grade footage autonomously.
- Improve SLAM: Motion-aware models could enhance simultaneous localization and mapping by distinguishing between camera-induced motion and object motion.
- Collaborate in swarms: When drones understand their own motion, they can better coordinate with others in dynamic environments.
Limitations: Not Perfect Yet
As with all research, there are trade-offs and areas for improvement:
- Synthetic data bias: The dataset relies on simulations, which may not perfectly translate to real-world conditions.
- Hardware constraints: Extracting 3D cues from
VGGTadds computational overhead that might limit use on lightweight drone hardware. - Limited primitives: The motion categories are predefined, so unusual or complex motions might not be recognized.
- Environmental challenges: Poor lighting or fast motion could degrade performance.
For real-world deployment, more robust generalization and hardware optimization are needed.
Can Hobbyists Try It?
Surprisingly, advanced hobbyists might find these methods quite accessible:
- Hardware: You'll need a drone with a decent onboard GPU, a camera (of course), and the ability to run 3D models like
VGGT. Something like the Nvidia Jetson platform might work. - Software: The dataset and benchmark are available on
Hugging Face, and the pipeline is model-agnostic, so you can integrate it with existing VideoLLMs likeFlamingo. - Barrier: The main challenge is processing power—extracting cues from a 3D model isn’t lightweight.
Related Work
This isn’t the only paper tackling motion and scene understanding. Here are two complementary reads:
- “Towards Spatio-Temporal World Scene Graph Generation from Monocular Videos”: This explores building 3D spatio-temporal graphs, which could combine well with the motion-awareness described here.
- “Out of Sight, Out of Mind? Evaluating State Evolution in Video World Models”: Focuses on maintaining scene consistency over time, even with occlusions—vital for drones operating in dynamic spaces.
Final Thoughts
If drones could not only see but understand how their cameras move, the possibilities for smarter navigation, filmmaking, and collaboration expand dramatically. The lightweight, model-agnostic approach here brings us one step closer—but real-world testing will determine how far it can fly.
Paper Details
Title: Geometry-Guided Camera Motion Understanding in VideoLLMs
Authors: Haoan Feng, Sri Harsha Musunuri, Guan-Ming Su
Published: Not specified
arXiv: 2603.13119 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.