Unlock Drone Adaptability: Training-Free AI for Few-Shot Object Learning
This research significantly improves few-shot image classification for vision-language models like CLIP by intelligently mixing and aligning image and text prototypes, enabling drones to identify new objects with minimal examples without retraining.
TL;DR: This research significantly improves few-shot image classification for vision-language models like
CLIPby intelligently mixing and aligning image and text prototypes. It essentially teaches drones to identify new objects with minimal examples, without needing costly retraining, making them more adaptable on the fly.
Drones That Learn on the Fly: A Reality Check
Drones are getting smarter, but true adaptability remains a major hurdle. Imagine a drone needing to identify a new type of crop disease, a specific faulty component, or even an unfamiliar search-and-rescue target it's never seen before. Current AI often demands extensive, costly retraining for every new object. This paper tackles that problem head-on, delivering a method for "training-free" few-shot classification that lets existing vision-language models (VLMs) like CLIP learn new visual concepts with just a handful of examples.
The Heavy Burden of 'New' – Why Drones Struggle with Novelty
The core limitation for autonomous drones today is their reliance on pre-trained models. When a drone encounters something new, something outside its training data, it's often stumped. Retraining these models for every new classification task is not just expensive and time-consuming, it's impractical for real-world deployment. You can't send a drone out for a mission, find a new target, then bring it back for a week of re-training. This 'catastrophic forgetting' or inability to adapt without full retraining is a major blocker for versatile, real-time drone operations. Existing few-shot methods using CLIP improve things, but they often struggle with noise from image data, like background clutter, leading to suboptimal performance. We need a way for drones to rapidly adapt to novel visual cues with minimal examples, directly on the edge, without significant computational overhead or compromising existing knowledge.
Shrinking the Noise: How CLIP Gets Smarter with Fewer Examples
The research builds on vision-language models (VLMs) like CLIP, which are designed to align text and image representations. The key idea here is to refine how CLIP uses these representations for few-shot classification. Traditionally, you might use text embeddings (e.g., "a photo of a drone") as prototypes for classification, or image embeddings from a few examples. This paper argues that directly mixing these image and text prototypes is more effective, acting like a shrinkage estimator to reduce variance.
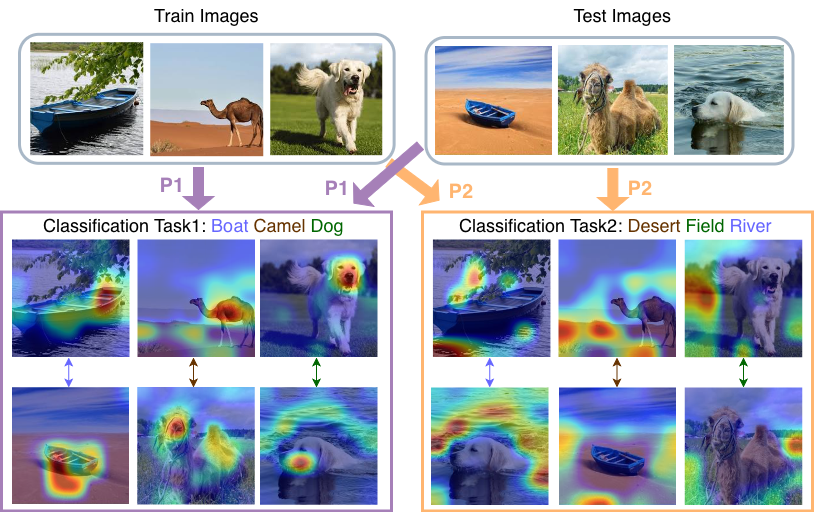 Figure 1: Given the classification problem, the image latent space should be differently exploited. The semantic space defined by the text prototypes defines a relevant subspace. We propose text-aligned semantic projection of image features which performs classification using only the relevant subspace. Task relevant regions denoted by attention maps are obtained by the proposed task-specific semantic projection P1 and P2.
Figure 1: Given the classification problem, the image latent space should be differently exploited. The semantic space defined by the text prototypes defines a relevant subspace. We propose text-aligned semantic projection of image features which performs classification using only the relevant subspace. Task relevant regions denoted by attention maps are obtained by the proposed task-specific semantic projection P1 and P2.
However, raw image prototypes often carry "noise" – instance-specific background or context that isn't relevant to the actual object being classified. To address this, the authors propose projecting image prototypes onto the principal directions of the semantic text embedding space. Think of it as filtering the image data through the lens of what the text descriptions already understand. This creates "text-aligned semantic image subspaces," which helps the model focus on the truly relevant visual features.
 Figure 3: Attention maps computed using the ResNet-50 vision encoder of CLIP showing that the text-aligned features focus on the task-relevant information from the image and the orthogonal part on remaining parts of image.
Figure 3: Attention maps computed using the ResNet-50 vision encoder of CLIP showing that the text-aligned features focus on the task-relevant information from the image and the orthogonal part on remaining parts of image.
This process ensures that the model concentrates on the object itself, rather than its surroundings. But what if the initial CLIP alignment between text and image isn't perfect for a specific, niche drone dataset? The paper acknowledges that "semantic alignment might be suboptimal" in such cases. To counteract this, they also leverage the image subspace by modeling its anisotropy using class covariances, effectively adding an LDA (Linear Discriminant Analysis) classifier. This LDA component helps distinguish classes even when the text-aligned features aren't perfectly separated.
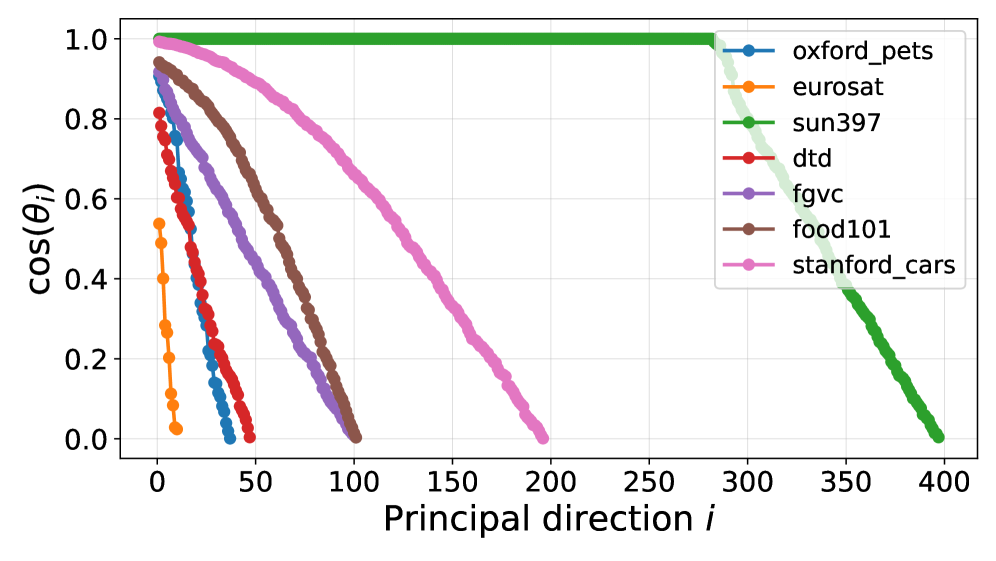 Figure 5: Cosine similarity between image and text embedding spaces using CLIP-B/16.
Figure 5: Cosine similarity between image and text embedding spaces using CLIP-B/16.
The core contribution is TAMP+LDA, which combines a text-aligned mixed prototype classifier with an image-specific LDA classifier. This dual approach provides robustness, leveraging both the general semantic knowledge from CLIP and the specific visual distinctions within the few-shot examples.
Real-World Gains: The Numbers Speak for Themselves
The paper demonstrates significant improvements across various few-shot classification benchmarks. For instance, mixing prototypes alone substantially reduces the Mean Squared Error (MSE) compared to a simple Nearest Centroid Mean (NCM) classifier, especially with more shots.
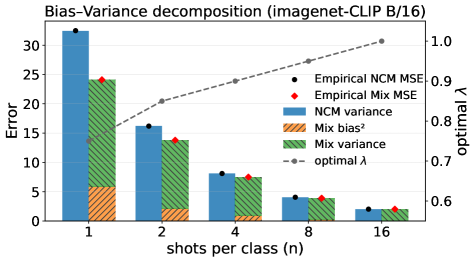 Figure 2: MSE of NCM and mixed prototypes as a function of the number of shots using CLIP-B/16.
Figure 2: MSE of NCM and mixed prototypes as a function of the number of shots using CLIP-B/16.
The impact of aligning and mixing prototypes is clear:
- Improved Accuracy: The combination of alignment and mixing consistently boosts classification accuracy across diverse datasets. Figure 4 shows the "Align+Mix" strategy generally outperforming "Mix" or "Align" alone.
- Robustness Across Datasets: The proposed
TAMP+LDAmethod (Text-Aligned Mixed Prototype + LDA) outperforms existing methods on 9 different datasets, including challenging fine-grained classification tasks. - Clear Gains with LDA: Ablation studies in Figure 7 highlight the positive impact of incorporating
LDAin the image space, especially when combined with the text-orthogonal image subspace. - ViT-B/16 Performance: With the
CLIP ViT-B/16model,Align+Mixprototypes show strong performance gains across most datasets (Figure 8), reinforcing the benefits of the combined strategy. - Outperforming Baselines: Figure 10 specifically shows
TAMPandTAMP+LDAclassifiers outperformingGDA(Generalized Discriminant Analysis) on 9 datasets, confirming its state-of-the-art performance for thisCLIPbackbone. - Impact of Subspaces: Analysis in Figure 9 reveals how different subspaces (aligned vs. orthogonal) contribute to performance, validating the method's design.
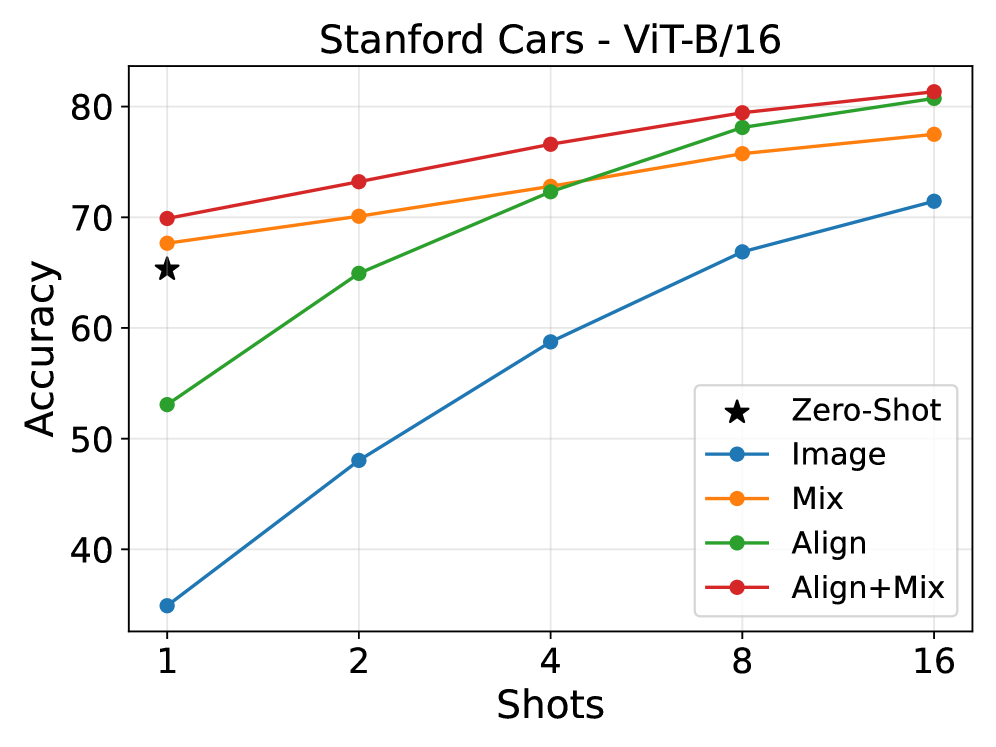 Figure 4: Impact of Alignment and Mixing on classification accuracy.
Figure 4: Impact of Alignment and Mixing on classification accuracy.
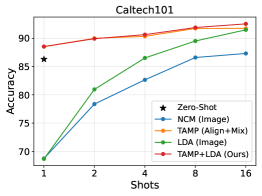 Figure 6: The impact of different classifiers on 9 datasets with CLIP-ResNet-50.
Figure 6: The impact of different classifiers on 9 datasets with CLIP-ResNet-50.
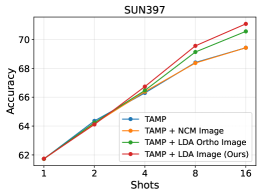 Figure 7: Ablation experiments showing the impact of using LDA in the image space and the text-orthogonal image subspace.
Figure 7: Ablation experiments showing the impact of using LDA in the image space and the text-orthogonal image subspace.
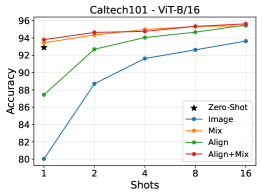 Figure 8: The impact of Align, Mix and Align+Mix prototypes on 9 datasets with CLIP ViT-B/16.
Figure 8: The impact of Align, Mix and Align+Mix prototypes on 9 datasets with CLIP ViT-B/16.
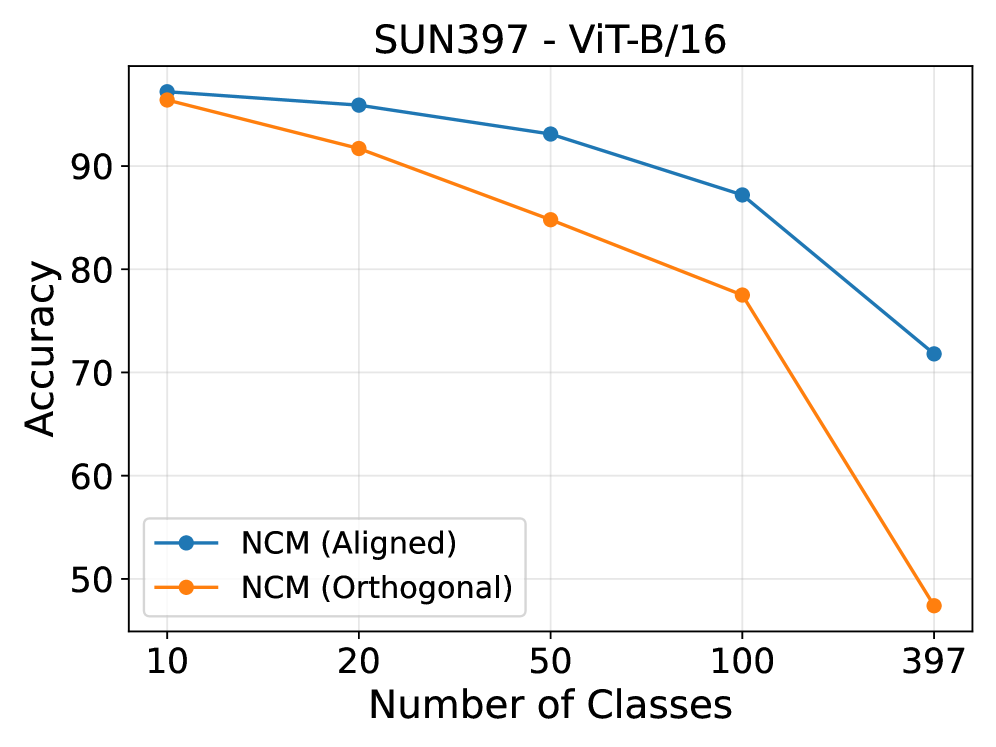 Figure 9: Analysis of the impact of aligned and orthogonal subspace with varying subsets of classes.
Figure 9: Analysis of the impact of aligned and orthogonal subspace with varying subsets of classes.
![Figure 10: Performance comparison of GDA [wanghard] with the proposed TAMP and TAMP+LDA classifiers on 9 datasets with CLIP ViT-B/16.](https://qawnehlcoileybzacnvr.supabase.co/storage/v1/object/public/article-covers/figures/unlock-drone-adaptability-training-free-ai-for-few-shot-object-learning-mn7f9suk/fig-9.png) Figure 10: Performance comparison of GDA [wanghard] with the proposed TAMP and TAMP+LDA classifiers on 9 datasets with CLIP ViT-B/16.
Figure 10: Performance comparison of GDA [wanghard] with the proposed TAMP and TAMP+LDA classifiers on 9 datasets with CLIP ViT-B/16.
Mission Ready: Unlocking True Adaptability for Your Drone
This research is a big step towards truly autonomous and adaptable drones. Imagine a drone in a search-and-rescue scenario needing to identify specific distress signals or unfamiliar debris types after a disaster. With this method, an operator could provide a few example images of the new target type, and the drone's onboard AI could adapt its classification capabilities instantly, without needing to be re-trained or connected to cloud resources.
For agricultural drones, this means identifying new crop diseases or specific weed variants with just a handful of visual examples, enabling rapid, targeted intervention. In infrastructure inspection, a drone could learn to spot novel types of corrosion or stress fractures on a bridge it's never seen before. The "training-free" aspect is crucial here; it means less developer time, lower computational costs, and more responsive drone systems. This directly translates to drones that are more versatile, capable of handling unexpected situations, and ultimately, more valuable in dynamic real-world missions.
The Unseen Edges: Where This Approach Still Needs Work
While promising, this approach isn't a silver bullet.
First, the performance still heavily relies on the quality of the initial CLIP embedding space. If the CLIP model itself has poor cross-modal alignment for a very specific, niche dataset (e.g., highly specialized industrial components), the improvements might be less pronounced, as the authors acknowledge. The "semantic alignment might be suboptimal" issue is real.
Second, while "training-free" in the sense of not needing backpropagation on the target task, it still requires the CLIP model itself, which is a large model. Deploying CLIP (or a distilled version) on edge hardware like drone companion computers (e.g., NVIDIA Jetson series or Qualcomm Flight platforms) can still be computationally intensive and power-hungry for real-time inference, especially for the image encoder part.
Third, the method focuses on static image classification. Drones operate in dynamic environments, and recognizing events or sequences of actions is the next frontier. While the related work points to video-language models, this paper doesn't directly address temporal classification.
Finally, the "few-shot" aspect means it needs some examples. Zero-shot performance would be even better, but few-shot is a practical compromise. The quality and diversity of these few examples are still critical for the method's success.
Building Your Own Adaptive Drone Brain: What It Takes
For hobbyists with powerful NVIDIA Jetson Orin Nano or NX boards, or Qualcomm Flight RB5 platforms, this approach is definitely within reach. The core CLIP model is publicly available, and the techniques described (prototype mixing, semantic projection, LDA) are implementable using standard machine learning libraries like PyTorch or TensorFlow and scikit-learn. There are open-source implementations of CLIP, and frameworks for few-shot learning are becoming more common. Replicating the full TAMP+LDA method would require a solid understanding of linear algebra and deep learning, but a determined builder could certainly experiment with it. The main bottleneck for hobbyists would be the computational resources needed to run CLIP's vision encoder in real-time, but smaller CLIP variants or quantized models are continually being released, making edge deployment more feasible.
Broader Horizons: How This Fits into the AI Drone Landscape
This work sits at the intersection of vision-language models and few-shot learning, a rapidly evolving field. For instance, the discussion of the quality of visual input is highly relevant to "Vision-Language Models vs Human: Perceptual Image Quality Assessment" by Mehmood et al. For a drone to effectively classify, it first needs reliable sensor data. An onboard quality assessment system could ensure the inputs to few-shot classifiers are trustworthy. Beyond static classification, the idea of a drone building an 'episodic memory' to contextualize its few-shot learning over longer missions aligns well with "Chameleon: Episodic Memory for Long-Horizon Robotic Manipulation" by Guo et al., which explores memory for robotic tasks. This suggests a future where few-shot classification isn't just a point-in-time decision but part of a continuous learning process. Furthermore, the practical application of visual classification in agriculture, as seen in "The role of spatial context and multitask learning in the detection of organic and conventional farming systems based on Sentinel-2 time series" by Hemmerling et al., provides a tangible scenario where our main paper's 'training-free few-shot classification' would be invaluable for identifying specific crop issues without extensive pre-training.
The future of drone autonomy depends on systems that can learn and adapt without constant human intervention or expensive retraining. This paper pushes us closer to that reality, offering a robust method for drones to interpret new visual information on the fly.
Paper Details
Title: Cross-Modal Prototype Alignment and Mixing for Training-Free Few-Shot Classification Authors: Dipam Goswami, Simone Magistri, Gido M. van de Ven, Bartłomiej Twardowski, Andrew D. Bagdanov, Tinne Tuytelaars, Joost van de Weijer arXiv: 2603.24528 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.