Vega: Natural Language Control for Drones? Beyond the Joystick
A new model, Vega, allows autonomous systems to follow natural language instructions for personalized control, moving beyond pre-programmed paths to truly adaptive, spoken commands. While developed for driving, its implications for drone autonomy are significant.
TL;DR: Researchers introduced Vega, a new Vision-Language-World-Action model designed to help autonomous systems understand and act on complex natural language instructions. This moves us closer to a future where you can simply tell your drone what to do, rather than relying on joysticks or rigid pre-programmed missions.
Controlling a drone often feels like a delicate dance between joystick inputs, flight modes, and pre-programmed waypoints. But what if you could simply tell your drone what to do, in plain English? New research from Zuo et al. introduces Vega, a system designed to interpret and act on natural language commands. While initially developed for autonomous driving, Vega's potential for intelligent aerial platforms is significant. It's about shifting from rigid programming to fluid, intuitive interaction with your drones.
Why Drones Still Need a Human Touch (Mostly)
Today's autonomous drones, while incredibly capable, largely operate within predefined parameters. You can program a flight path, set up object tracking, or initiate return-to-home, but adapting to unforeseen circumstances or expressing nuanced mission objectives often demands manual intervention or complex re-programming. Current vision-language models in autonomy typically focus on describing scenes or high-level reasoning. They might tell you what they see or why they might take an action, but they aren't designed to directly accept diverse, personalized instructions such as "fly closer to the building, but maintain a safe distance from that antenna" or "scan the perimeter slowly, prioritizing the northern section first." This gap restricts the true flexibility and personalization of autonomous operations, whether on the road or in the air.
Inside Vega: How It Hears Your Commands
The Vega model tackles this challenge by integrating vision, language, world modeling, and action planning into a single, unified framework. Its core innovation bridges the gap between descriptive understanding and directive execution. To achieve this, the research team first built InstructScene, a massive dataset of around 100,000 driving scenarios, each meticulously annotated with diverse natural language instructions and corresponding optimal trajectories.
Vega itself functions as a Vision-Language-World-Action model. It employs a hybrid approach: an autoregressive paradigm processes visual inputs and language instructions, enabling it to understand context and intent. Simultaneously, a diffusion paradigm handles the generative aspects – predicting future world states and generating the specific action trajectories needed to follow an instruction. Crucially, the model uses joint attention mechanisms to foster deep interaction between the different modalities (vision, language, future predictions, and actions) and individual projection layers to give each modality specific capabilities. This allows Vega to not just understand instructions, but also to predict how the environment will change and generate the necessary flight path.
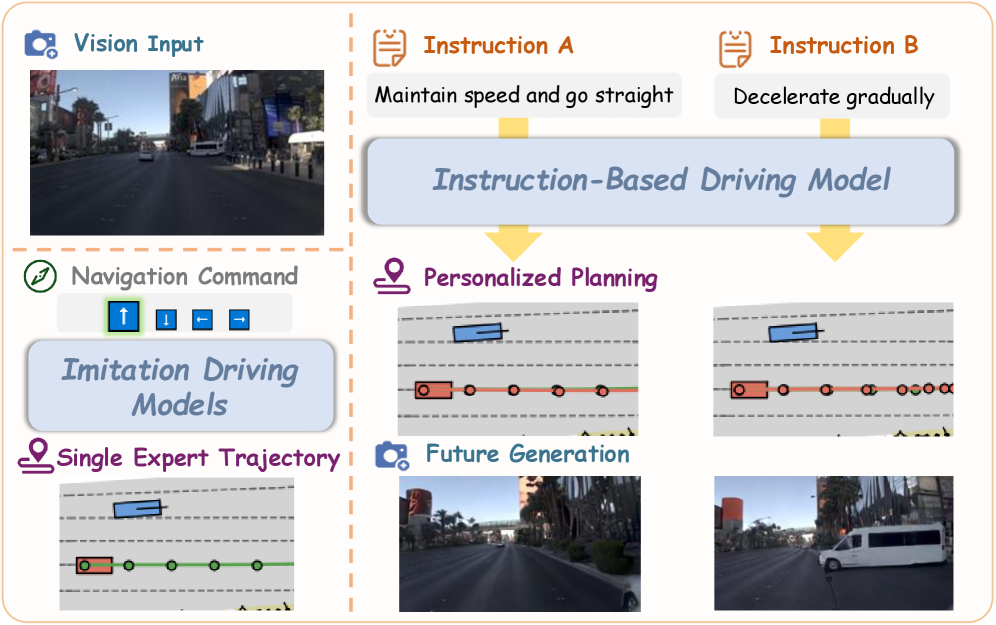 Figure 1: Overview of our model. Compared to traditional imitation driving models, which can only predict the single expert trajectory, Vega can follow natural language instructions to generate diverse planning trajectories and future image predictions.
Figure 1: Overview of our model. Compared to traditional imitation driving models, which can only predict the single expert trajectory, Vega can follow natural language instructions to generate diverse planning trajectories and future image predictions.
![Framework of our Unified Vision-Language-World-Action Model. We jointly model action planning and image generation using multi-modal inputs and a MoT architecture [38].](https://qawnehlcoileybzacnvr.supabase.co/storage/v1/object/public/article-covers/figures/vega-natural-language-control-for-drones-beyond-the-joystick-mn8upksj/fig-1.png) Figure 2: Framework of our Unified Vision-Language-World-Action Model. We jointly model action planning and image generation using multi-modal inputs and a MoT architecture [38].
Figure 2: Framework of our Unified Vision-Language-World-Action Model. We jointly model action planning and image generation using multi-modal inputs and a MoT architecture [38].
The model's ability to generate both future images and actions is a critical component. This means Vega isn't merely reacting; it's actively planning and simulating the outcome of its actions based on your instructions. This predictive capability is vital for complex autonomous tasks, especially in dynamic environments.
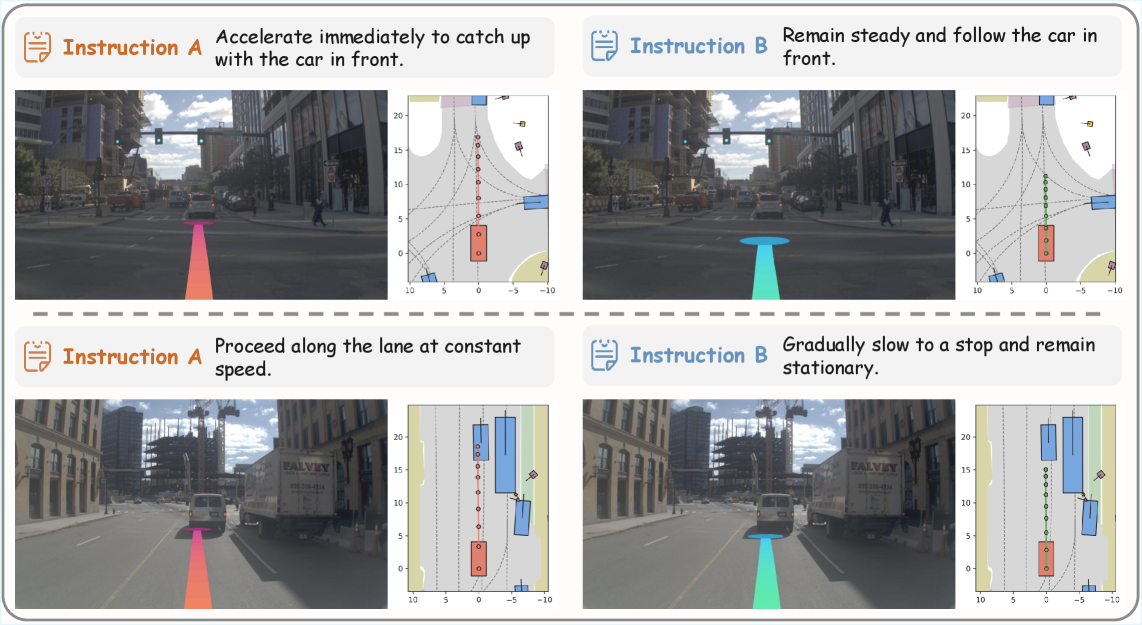 Figure 4: Instruction-based planning examples. We visualize the effects of language instructions on action planning with front-view camera images and BEV maps.
Figure 4: Instruction-based planning examples. We visualize the effects of language instructions on action planning with front-view camera images and BEV maps.
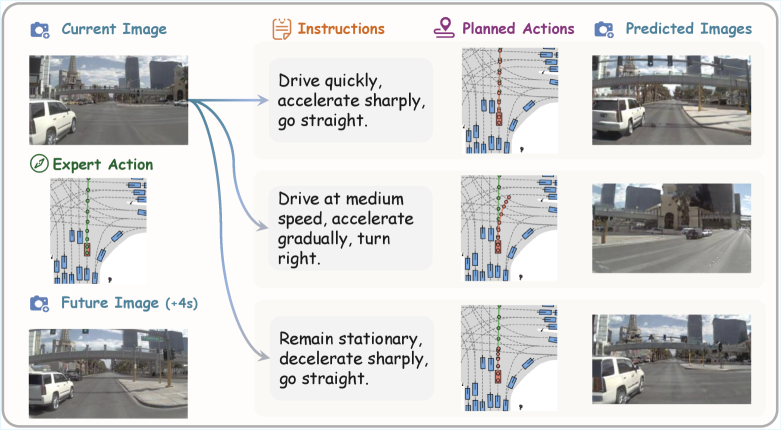 Figure 5: Future image generation conditioned on instructions and actions. In the same scenario, given two sets of instructions, the model plans two action sequences and generates their respective future images. Both action sequences follow their instructions and both images are consistent with their actions.
Figure 5: Future image generation conditioned on instructions and actions. In the same scenario, given two sets of instructions, the model plans two action sequences and generates their respective future images. Both action sequences follow their instructions and both images are consistent with their actions.
Beyond Simple Commands: What Vega Achieves
The experiments demonstrate Vega's superior planning performance and strong instruction-following abilities. The researchers specifically highlight its capacity to generate diverse planning trajectories based on varied instructions, a task traditional imitation learning models often struggle with. For instance, given the same scene, Vega can generate distinct flight paths depending on whether the instruction is to "fly cautiously" or "proceed aggressively."
This goes beyond merely following simple commands; it's about understanding nuance and intent. The model demonstrates it can adapt its behavior and predict future outcomes consistent with those instructions. This level of adaptability is crucial for real-world drone operations where conditions are rarely static and mission parameters can shift rapidly.
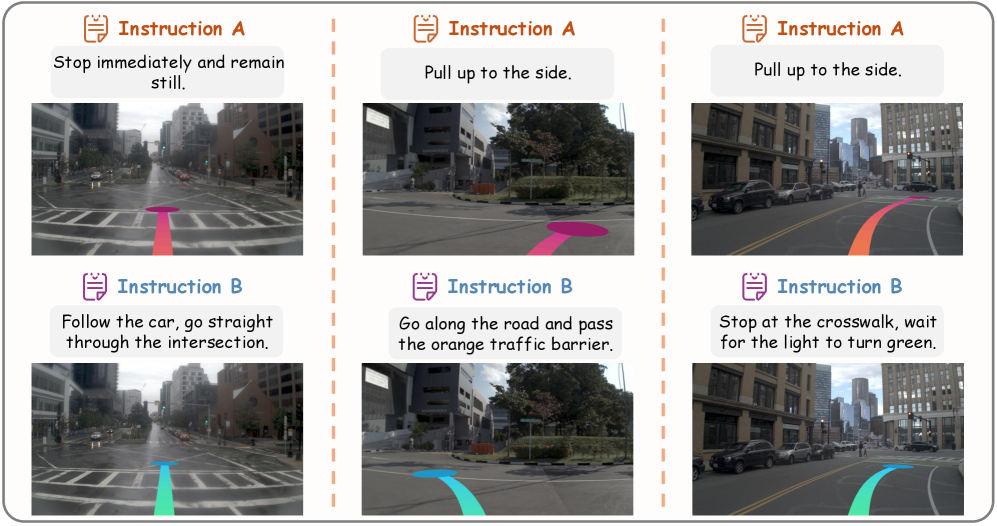 Figure 6: A bird's-eye view (BEV) representation of a driving scenario, illustrating the model's perception of the environment and planned trajectory, likely influenced by a specific natural language instruction.
Figure 6: A bird's-eye view (BEV) representation of a driving scenario, illustrating the model's perception of the environment and planned trajectory, likely influenced by a specific natural language instruction.
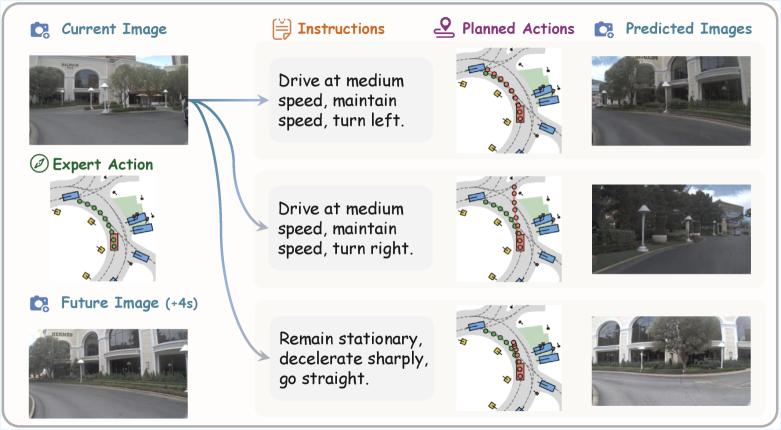 Figure 7: A visual representation of Vega's capabilities, potentially showing instruction interpretation or action planning.
Figure 7: A visual representation of Vega's capabilities, potentially showing instruction interpretation or action planning.
From Roads to Skies: Vega's Drone Potential
For drone hobbyists, builders, and engineers, Vega offers a significant leap towards intuitive and flexible drone control. Consider these possibilities:
- Complex Inspections: Instead of meticulously pre-programming a flight path around a wind turbine, you could simply tell your drone, "Inspect the top two blades, paying close attention to any leading-edge damage, then return to base." The drone would interpret "paying close attention" to mean a slower, closer flight path.
- Search and Rescue: A rescuer might command, "Scan sector C at 50 meters altitude, prioritize thermal anomalies, report any signs of movement immediately." The drone would adapt its flight pattern and sensor usage based on the instruction.
- Adaptive Cinematography: A filmmaker could direct, "Track the subject from above, slowly spiraling down while keeping them centered, then pull back to a wide shot of the landscape." This moves beyond basic follow-me modes to dynamic, creative control.
This technology could transform drones into more collaborative tools, responding directly to human intent rather than requiring rigid, pre-defined scripts. It expands the capabilities of autonomous drones, making them more accessible and powerful for a wider range of applications.
Grounding Vega: Challenges and Next Steps
While Vega shows immense promise, it also faces limitations, many of which are common in large-scale AI models. First, its reliance on a massive, annotated dataset like InstructScene implies significant data collection and labeling costs. Generalizing this to the vast diversity of drone environments—forests, urban canyons, industrial sites, and more—would require similarly extensive, specialized datasets. This is no small undertaking.
Second, the computational overhead of such a comprehensive Vision-Language-World-Action model, with its autoregressive and diffusion components, is likely substantial. Deploying this on a mini-drone with strict weight, power, and real-time processing constraints would present a significant engineering challenge. Edge AI optimizations would be crucial.
Finally, autonomous driving operates in a relatively structured environment compared to the complex, three-dimensional nature of drone flight. Factors like wind, complex airflows, and varied terrain present unique challenges not fully captured by a driving dataset. Ensuring safety-critical performance for novel, uninstructed scenarios or ambiguous commands would demand rigorous testing and robust error handling beyond what's presented in this initial research.
For the Makers: Is Vega a DIY Dream?
Replicating Vega from scratch is well beyond the scope of a typical hobbyist or even a small team without substantial resources. Creating a 100,000-scene dataset, training a complex multi-modal model, and deploying it on custom hardware represent an enormous undertaking. While the underlying concepts of vision-language processing and diffusion models are open research areas, the specific Vega architecture and InstructScene dataset are proprietary to the research team. A hobbyist could, however, experiment with smaller, open-source vision-language models like CLIP or LLaVA combined with off-the-shelf drone flight controllers and ROS (Robot Operating System) for basic instruction parsing and command generation. But achieving Vega's level of nuanced instruction following and predictive capabilities would require significant computational power and deep expertise in machine learning and robotics. For now, this remains firmly in the realm of advanced academic and industrial research.
Vega in Context: Other AI Pushing the Envelope
This work doesn't exist in a vacuum; it builds on and relates to other critical advancements in autonomous AI. For instance, the challenge of personalizing autonomous systems is explored in "Drive My Way: Preference Alignment of Vision-Language-Action Model for Personalized Driving." That paper focuses on adapting a system's 'driving style'—or in our case, 'flying style'—based on user preferences, directly complementing Vega's instruction-following capabilities. If Vega tells your drone where to go, Drive My Way could dictate how to go: smoothly, aggressively, or cautiously.
Reliable understanding of instructions also requires consistent reasoning across different inputs. "R-C2: Cycle-Consistent Reinforcement Learning Improves Multimodal Reasoning" addresses this by ensuring that models like Vega don't produce contradictory predictions when processing visual and textual data. This robust multimodal reasoning is fundamental for a drone to consistently interpret and act upon complex commands.
Finally, for advanced mission execution, a drone needs to understand specific events in its environment. "SlotVTG: Object-Centric Adapter for Generalizable Video Temporal Grounding" could allow a Vega-powered drone to not just follow instructions but also to process queries like "report when the package is dropped" or "monitor for activity after landing," adding a layer of event-based intelligence to its capabilities.
Vega brings us closer to a future where drones are not just tools, but intelligent partners. What specific tasks would you entrust to a drone that truly understands your voice?
Paper Details
Title: Vega: Learning to Drive with Natural Language Instructions Authors: Sicheng Zuo, Yuxuan Li, Wenzhao Zheng, Zheng Zhu, Jie Zhou, Jiwen Lu Published: March 2026 (arXiv v1) arXiv: 2603.25741 | PDF
Figure 8: Logo of an unnamed entity, likely the research institution or project.
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.