DriveTok: Tokenizing 3D Reality for Smarter Drone Autonomy
DriveTok introduces an efficient 3D scene tokenizer that unifies multi-view reconstruction and understanding for autonomous systems. It converts complex multi-camera visual data into compact, information-rich scene tokens, enabling advanced spatial awareness for AI models.
Building a World Model for Your Drone
TL;DR: DriveTok efficiently tokenizes complex 3D driving scenes from multiple camera views, creating compact "scene tokens" that unify geometric, semantic, and textural information. This approach is critical for building robust "world models" for autonomous systems, moving beyond simple 2D perception to a deeper, multi-dimensional understanding of environments.
For drone hobbyists and engineers, the vision of a truly autonomous drone often hinges on its ability to "understand" its surroundings, not just react to them. We’re talking about building an internal "world model" – a rich, dynamic representation of the 3D environment that allows an AI to predict, plan, and interact intelligently. This is a monumental task, especially when dealing with the torrent of data from multiple onboard cameras. A new paper, "DriveTok," offers a compelling step towards this goal by introducing an efficient method for turning that raw visual data into a concise, meaningful language its AI can speak.
The Limitations of Two Dimensions
Current approaches to visual processing for autonomous systems often fall short when scaled to real-world complexity. Most existing tokenizers are designed for simpler, monocular, 2D scenes. When applied to high-resolution, multi-view driving (or flying) scenarios, they become inefficient and struggle with "inter-view inconsistency." Consider a drone with six cameras; each camera sees a slightly different perspective, and integrating those views into a single, coherent 3D understanding is a major challenge. This inconsistency means an AI might get conflicting information about an obstacle's position or a terrain feature, leading to unreliable navigation, wasted processing power, and ultimately, less robust autonomy. Drones, particularly, demand precise 3D awareness to operate safely and effectively in dynamic, unstructured environments, and current 2D-centric methods just don't cut it.
How DriveTok Builds a 3D World Language
DriveTok tackles this by creating a unified 3D representation directly from multi-view inputs. The system starts by feeding surround-view images into an encoder. This encoder leverages existing vision foundation models to extract semantically rich visual features – essentially, it pulls out the meaningful details from the raw pixels.
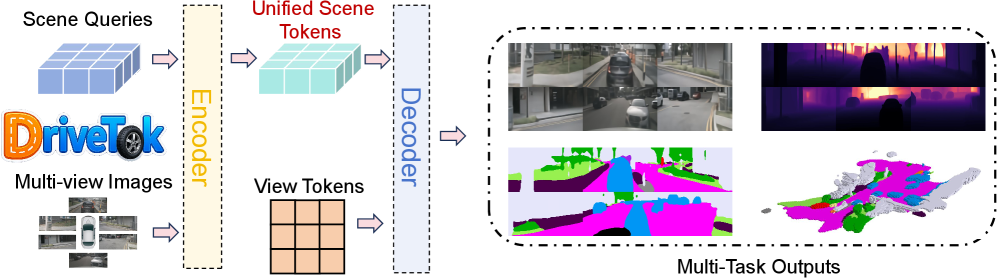 Figure 2: Illustration of DriveTok. DriveTok processes multi-view images and scene queries through an encoder-decoder architecture to produce unified scene tokens and generate diverse autonomous driving scene reconstruction and understanding outputs.
Figure 2: Illustration of DriveTok. DriveTok processes multi-view images and scene queries through an encoder-decoder architecture to produce unified scene tokens and generate diverse autonomous driving scene reconstruction and understanding outputs.
These features are then transformed into what the authors call "scene tokens." This tokenization isn't a simple flattening; it's a sophisticated process using 3D deformable cross-attention. This mechanism allows the model to selectively focus on relevant information across different camera views and project it into a shared 3D space. This process intelligently merges what each camera sees into a single, compact descriptor of the 3D scene.
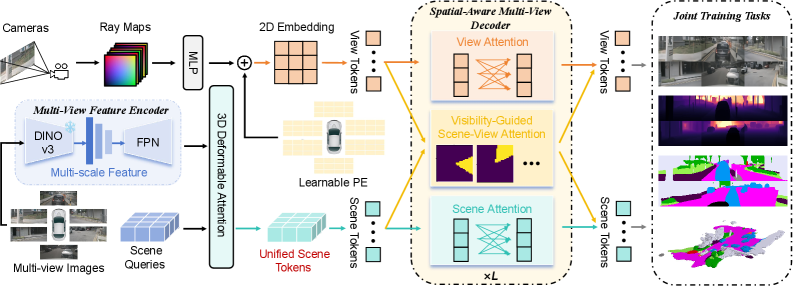 Figure 3: Overview of DriveTok. Surround-view images are encoded by a 3D scene encoder. view tokens (with learnable and Plücker-ray embeddings) and scene tokens interact through a spatial-aware multi-view transformer with visibility-guided scene-view attention. Joint pretraining uses image reconstruction, depth prediction, semantic prediction, and occupancy prediction.
Figure 3: Overview of DriveTok. Surround-view images are encoded by a 3D scene encoder. view tokens (with learnable and Plücker-ray embeddings) and scene tokens interact through a spatial-aware multi-view transformer with visibility-guided scene-view attention. Joint pretraining uses image reconstruction, depth prediction, semantic prediction, and occupancy prediction.
For the system to truly "understand" the scene, it also needs to be able to reconstruct it. DriveTok employs a multi-view transformer for decoding. From those compact scene tokens, this transformer can reconstruct various outputs: RGB images, depth maps, and semantic segmentation maps for each camera view. This reconstruction capability is crucial because it forces the scene tokens to retain rich, detailed information about the environment.
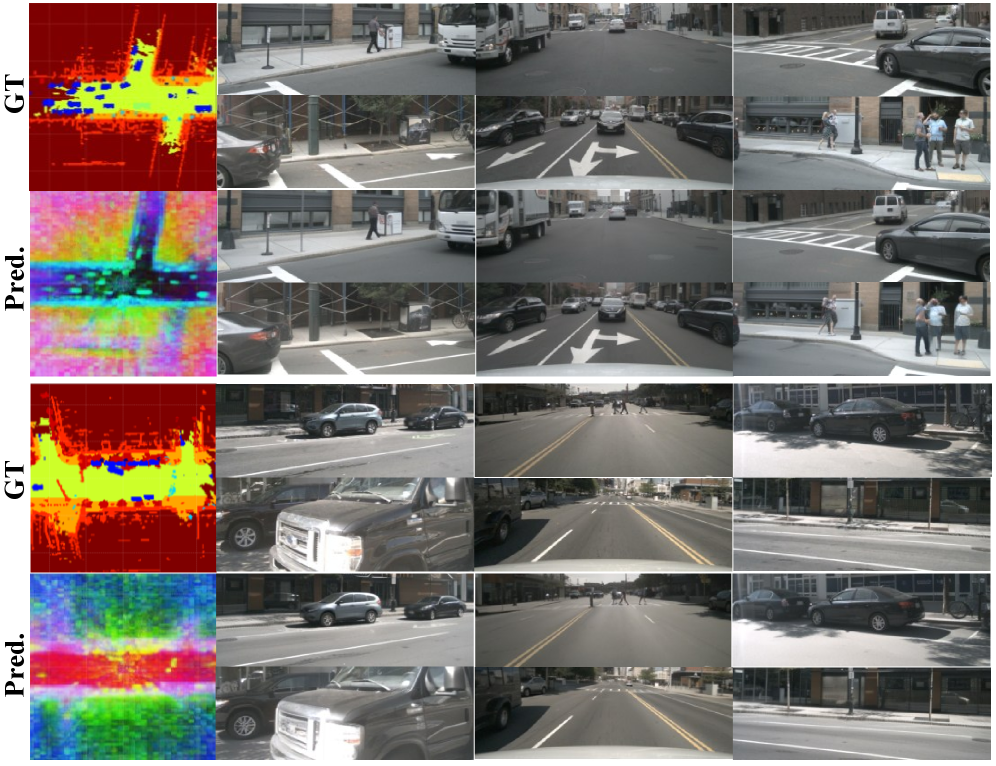 Figure 4: Visualizations of BEV scene tokens and images. We visualize the BEV feature maps with PCA, the ground truth labels for semantic regularization and the decoded images v.s. ground truth images. The PCA result clearly shows that our BEV scene tokens not only learns the complex textures but also models the semantic structure of the driving scenes, avoiding radial patterns in conventional methods.
Figure 4: Visualizations of BEV scene tokens and images. We visualize the BEV feature maps with PCA, the ground truth labels for semantic regularization and the decoded images v.s. ground truth images. The PCA result clearly shows that our BEV scene tokens not only learns the complex textures but also models the semantic structure of the driving scenes, avoiding radial patterns in conventional methods.
Beyond 2D reconstructions, DriveTok also integrates a 3D head that operates directly on the scene tokens to predict 3D semantic occupancy. This means it can build a volumetric understanding of the environment, knowing not just what objects are present, but their precise 3D location and extent. This joint training across multiple objectives – image reconstruction, depth, semantics, and 3D occupancy – ensures that the learned scene tokens are incredibly rich, integrating semantic, geometric, and textural information into a unified, efficient representation. The system also uses "visibility-guided scene-view attention" and "Plücker-ray embeddings" to improve spatial awareness and consistency across views, ensuring that information is correctly mapped from 2D camera images to the 3D scene tokens, even accounting for occlusions.
 Figure 5: Visualizations of DriveTok in different tasks. We provide a holistic visualization of our DriveTok in diverse autonomous driving scene reconstruction and understanding tasks. They show that DriveTok effectively represents the overall 3D environment by constructing scene tokens, thereby maintaining strong multi-view consistency. Through joint task training, the learned scene tokens not only capture texture details in the image space but also achieve a deeper perception and understanding.
Figure 5: Visualizations of DriveTok in different tasks. We provide a holistic visualization of our DriveTok in diverse autonomous driving scene reconstruction and understanding tasks. They show that DriveTok effectively represents the overall 3D environment by constructing scene tokens, thereby maintaining strong multi-view consistency. Through joint task training, the learned scene tokens not only capture texture details in the image space but also achieve a deeper perception and understanding.
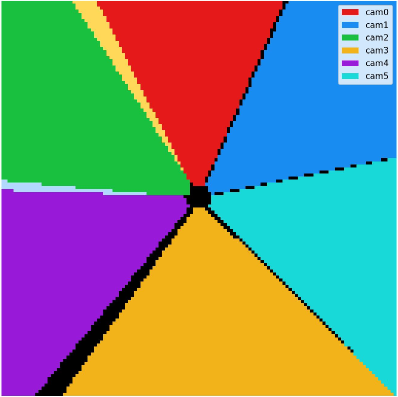 Figure 6: Visualization of visibility-guided mask. Each color corresponds to the region in the BEV plane that is visible from a particular camera, forming six wedge-shaped sectors that meet at the ego-vehicle center. The black region at the center corresponds to areas not visible to any camera. In addition, any colors outside these six primary sectors represent boundary zones where multiple camera frustums overlap.
Figure 6: Visualization of visibility-guided mask. Each color corresponds to the region in the BEV plane that is visible from a particular camera, forming six wedge-shaped sectors that meet at the ego-vehicle center. The black region at the center corresponds to areas not visible to any camera. In addition, any colors outside these six primary sectors represent boundary zones where multiple camera frustums overlap.
Performance Highlights: What DriveTok Achieves
The effectiveness of DriveTok was rigorously tested on the widely used nuScenes dataset, a benchmark for autonomous driving perception. The abstract claims "extensive experiments" demonstrating strong performance across its multi-task objectives. Specifically, the scene tokens generated by DriveTok performed well on:
- Image Reconstruction: The ability to accurately reconstruct the original multi-view images from the tokens indicates that rich textural and visual details are preserved.
- Semantic Segmentation: DriveTok successfully identified and segmented different objects and regions within the scene, showing strong semantic understanding.
- Depth Prediction: Accurate depth maps were generated, confirming the geometric fidelity encoded in the tokens.
- 3D Occupancy Prediction: The system could reliably predict the volumetric layout of the environment, crucial for path planning and collision avoidance.
Qualitatively, visualizations (like Figure 4 and 5) show that DriveTok's BEV (Bird's Eye View) scene tokens capture complex textures and semantic structures, avoiding the radial distortion patterns often seen in conventional BEV methods. This multi-task capability, derived from a single set of unified scene tokens, underscores the system's robust and consistent representation of the 3D environment, even in challenging conditions like night-time scenes (Figure 7).
 Figure 7: Visualizations of DriveTok in different tasks. Each column corresponds to a different autonomous driving scenario, including challenging night-time scenes. These results illustrate that DriveTok can generate coherent 2D and 3D predictions across diverse tasks from our unified scene tokens.
Figure 7: Visualizations of DriveTok in different tasks. Each column corresponds to a different autonomous driving scenario, including challenging night-time scenes. These results illustrate that DriveTok can generate coherent 2D and 3D predictions across diverse tasks from our unified scene tokens.
Why This Matters for Drones
For drone builders and engineers, DriveTok's implications are significant. Drones, especially those for inspection, delivery, or complex cinematography, often rely on multiple cameras for a comprehensive view. This paper offers a pathway to making sense of that multi-view data in a truly 3D, unified manner.
- Advanced World Models: By providing a compact, information-rich tokenized representation of the 3D environment, DriveTok could become the visual front-end for sophisticated "world models" in drone AI. This means drones could predict future states of their environment, understand object interactions, and plan complex trajectories with unprecedented accuracy.
- Enhanced Autonomous Navigation:
SLAM(Simultaneous Localization and Mapping) and path planning could benefit immensely. Instead of processing individual camera streams, an autonomous drone could work with a unified 3D token stream, leading to more robust obstacle avoidance, precise hovering, and confident navigation through cluttered spaces like dense forests or urban canyons. - Efficient Data Processing: Compacting high-resolution multi-view data into efficient scene tokens could significantly reduce the computational load for downstream
Vision-Language-Action (VLA)models or other AI components on the drone. This is crucial for power-constrained platforms. - Robotic Manipulation: Drones equipped with robotic arms for tasks like infrastructure inspection or package delivery would gain a much deeper understanding of object geometry and semantics, enabling more precise and delicate interactions. For instance, a drone could identify a specific component on a wind turbine, understand its 3D form, and then precisely position a robotic arm for a maintenance task.
Real-World Hurdles and Unanswered Questions
While DriveTok presents a compelling solution, it's important to consider its current limitations, especially when thinking about drone deployment.
- Domain Specificity: The paper explicitly focuses on "autonomous driving systems" and was evaluated on the
nuScenesdataset, which consists of urban driving environments. How well DriveTok generalizes to the vastly different and often more complex environments drones operate in—like dense foliage, high altitudes, dynamic weather conditions, or indoor spaces—remains an open question. The semantic categories and typical scene layouts differ significantly. - Computational Overhead: While the abstract mentions "efficiency" of tokenization, the underlying architecture involves
3D deformable cross-attentionandmulti-view transformers. These are computationally intensive operations, typically requiring powerfulGPUsfor real-time performance. Mini drones, and even larger UAVs, operate under strict power and weight constraints. Deploying this on drone-gradeedge AIhardware like anNVIDIA Jetson OrinorQualcomm Snapdragon Flightwould require significant optimization or a drastic reduction in model size. - Dynamic Environments Beyond Driving: Autonomous driving scenes have their own dynamics (cars, pedestrians), but drone environments can be even more chaotic, involving fast-moving small objects, highly deformable surfaces (e.g., fabric flapping), or rapid changes in lighting. The paper doesn't detail how robustly DriveTok handles these extreme dynamics.
- Hardware and Calibration: Achieving accurate multi-view perception relies heavily on precise camera calibration and synchronization, which can be challenging to maintain on a drone subject to vibrations and environmental changes. The system implicitly assumes perfectly calibrated cameras, which is not always a given in real-world drone operations.
Is This a DIY Project? (Spoiler: No)
For the typical drone hobbyist, replicating DriveTok from scratch is highly impractical, if not impossible. The development involves deep expertise in computer vision, transformer architectures, and 3D scene understanding. Training such a model requires access to massive, annotated 3D datasets like nuScenes and substantial computational resources, likely clusters of high-end GPUs running for weeks. This is firmly in the realm of academic research labs and well-funded industry teams.
However, if the authors release their code and pre-trained models, a more advanced hobbyist or small engineering team might be able to fine-tune the model for specific drone applications, assuming they have access to powerful edge AI hardware (e.g., NVIDIA Jetson AGX Orin) and smaller, domain-specific datasets. Even then, the complexity of managing multi-camera inputs and integrating the tokenized output into a real-time flight controller would be a significant engineering challenge. This isn't a project for a weekend build; it's a foundation for future commercial or research-level drone AI development.
DriveTok's Place in the AI Landscape
DriveTok isn't operating in a vacuum; it fits into a broader push for more intelligent autonomous systems. Its compact scene tokens are designed as an interface for Vision-Language-Action (VLA) models and world models. This makes it highly complementary to research like "Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding." That paper explores how models can leverage implicit 3D priors to achieve deeper geometric reasoning once they have a structured representation, precisely what DriveTok provides. Essentially, DriveTok gives the VLA model a clean, understandable input, and papers like "Generation Models Know Space" show what powerful insights can then be derived from it.
Furthermore, "Not All Features Are Created Equal: A Mechanistic Study of Vision-Language-Action Models" directly investigates how VLA models translate multimodal inputs, like DriveTok's visual tokens, into actions. This research offers crucial insight into how the tokenized information is actually processed to make decisions, connecting DriveTok's input to the drone's eventual behavior. And for enriching the very data that DriveTok tokenizes, "Under One Sun: Multi-Object Generative Perception of Materials and Illumination" is relevant. If DriveTok's input were to also contain rich information about materials and illumination, this "generative perception" would allow for even more nuanced scene tokens, enabling drones to understand not just geometry, but the physical properties of surfaces for tasks like grip assessment or solar panel inspection. Finally, the ambition of DriveTok for deeper scene understanding aligns with "DreamPartGen: Semantically Grounded Part-Level 3D Generation via Collaborative Latent Denoising," which focuses on understanding 3D objects as meaningful, semantically grounded parts. If DriveTok's tokens can represent a scene, then combining that with part-level understanding could allow a drone to interact with objects at a far more granular, functional level.
The Path Forward
DriveTok represents a compelling step toward equipping drones with a truly unified, 3D understanding of their complex environments. While the path to real-world drone deployment has challenges, the core idea of efficient 3D scene tokenization is a crucial building block for the next generation of highly autonomous, intelligent aerial platforms.
Paper Details
Title: DriveTok: 3D Driving Scene Tokenization for Unified Multi-View Reconstruction and Understanding Authors: Dong Zhuo, Wenzhao Zheng, Sicheng Zuo, Siming Yan, Lu Hou, Jie Zhou, Jiwen Lu Published: March 2026 arXiv: 2603.19219 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.