AutoGaze: Drones Learn to 'Gaze' for Efficient, High-Res Video AI
New research introduces AutoGaze, a module that allows AI models to selectively process critical parts of video, dramatically boosting efficiency and enabling high-resolution, long-form video understanding for drones.
TL;DR: Forget processing every pixel. AutoGaze is a new module that teaches AI models to 'gaze' at only the essential parts of high-resolution, long-form video, much like humans do. This dramatically cuts computational load, making advanced video understanding feasible for resource-constrained platforms like drones.
Smarter Vision for Smarter Drones
Drones are excellent at collecting visual data. Whether it's inspecting infrastructure, mapping terrain, or tracking objects, our mini aerial platforms capture more pixels than ever before. The challenge isn't just capturing this data, it's understanding it in real-time without draining batteries or requiring a supercomputer on board. This new work on AutoGaze proposes a critical step forward: giving drones the ability to selectively pay attention, just like a human operator would.
The Pixel Problem: Why Current AI Falls Short
Current AI models, especially Multi-modal Large Language Models (MLLMs) and Vision Transformers (ViTs), are powerful for video analysis. The problem? They're brute-force processors. They treat every single pixel and every frame in a video stream with equal importance. For long, high-resolution video streams—think 4K at 30 FPS—this leads to an explosion of data that quickly overwhelms even powerful GPUs. On a drone, this means prohibitive power consumption, heavy processing hardware, and significant latency.
Most of what a drone sees is redundant: static backgrounds, empty sky, or slow-moving elements that don't contribute much to the task at hand. This inefficiency limits real-time decision-making and pushes the dream of truly autonomous, intelligent drones further out of reach.
How AutoGaze Filters the Noise
AutoGaze tackles this by introducing a lightweight module that sits before the main ViT or MLLM. Its job is to filter out the noise, presenting only the essential visual information to the hungry AI model. It does this by "gazing"—autoregressively selecting a minimal set of multi-scale patches from the video frames. Think of it as an intelligent pre-processor that identifies what's important.
 Figure 1: AutoGaze selectively focuses on moving objects and adapts attention granularity based on scene detail, significantly reducing visual data while preserving key information.
Figure 1: AutoGaze selectively focuses on moving objects and adapts attention granularity based on scene detail, significantly reducing visual data while preserving key information.
The system is trained in two stages. First, a next-token prediction pre-training phase teaches AutoGaze to predict which patches are important. Then, a reinforcement learning (RL) post-training stage refines this by rewarding it for reconstructing the video within a user-defined error threshold using the fewest patches possible. This threshold is key; it allows you to balance detail against computational budget.
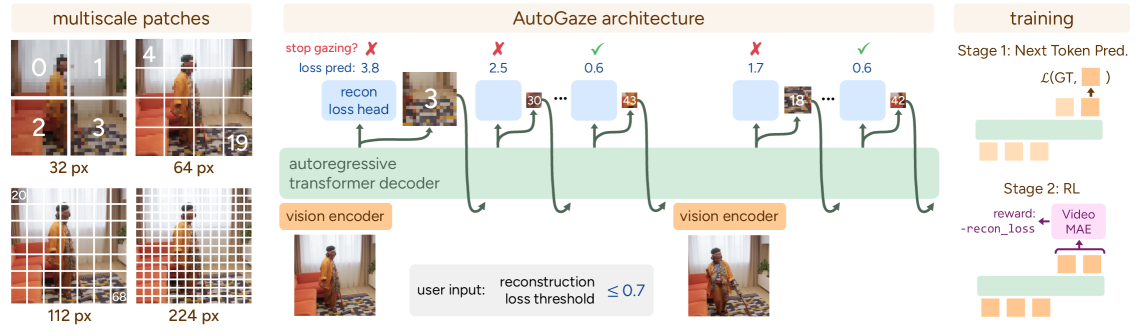 Figure 2: The AutoGaze module autoregressively selects multi-scale patches from each frame, stopping when sufficient information for reconstruction is gathered. Training involves next-token prediction and reinforcement learning for efficiency.
Figure 2: The AutoGaze module autoregressively selects multi-scale patches from each frame, stopping when sufficient information for reconstruction is gathered. Training involves next-token prediction and reinforcement learning for efficiency.
The intelligence behind its "gazing" isn't random. AutoGaze prioritizes areas with high optical flow—meaning motion. If something is moving, it's likely important. It also adapts its scale: coarser scales for larger movements, finer scales for detailed areas, much like our eyes scan a scene.
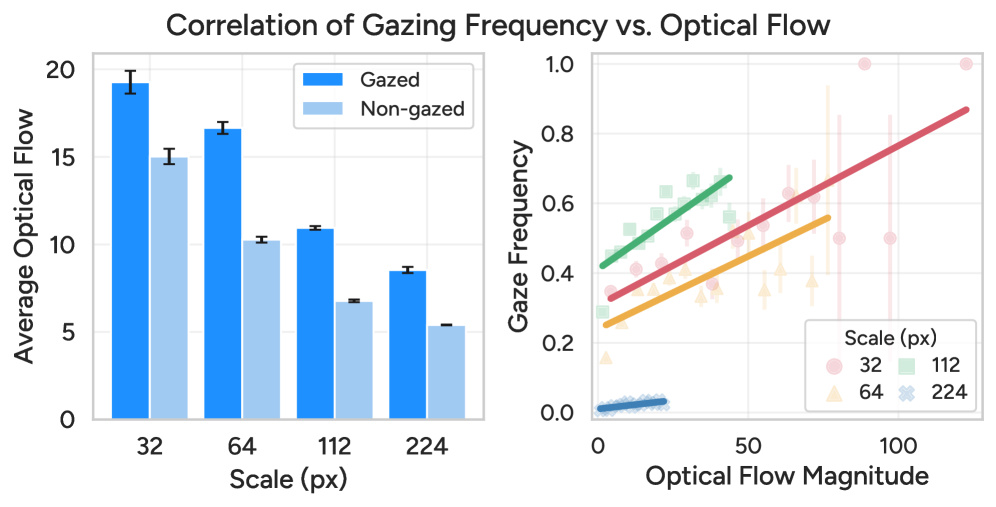 Figure 3: AutoGaze focuses on areas with higher optical flow, using coarser scales for larger movements and selecting patches more frequently in dynamic regions.
Figure 3: AutoGaze focuses on areas with higher optical flow, using coarser scales for larger movements and selecting patches more frequently in dynamic regions.
Critically, AutoGaze isn't just about motion; it also considers detail. Finer scales are used for patches with higher Laplacian variance, which signifies more intricate textures and edges. This combination of motion and detail ensures that relevant information isn't missed, whether it's a fast-moving object or a critical static detail.
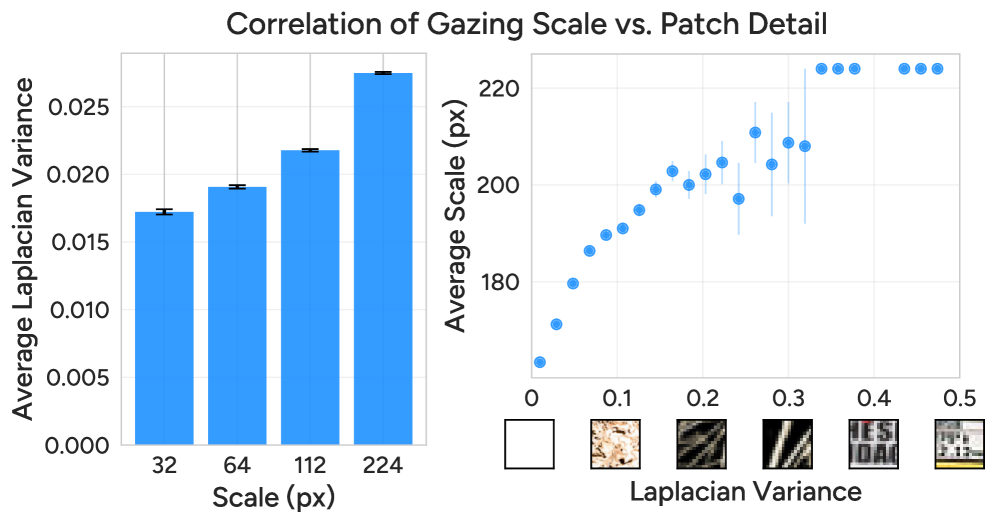 Figure 4: AutoGaze adjusts its gazing scale based on patch detail, selecting finer scales for more intricate regions and coarser scales for less detailed areas.
Figure 4: AutoGaze adjusts its gazing scale based on patch detail, selecting finer scales for more intricate regions and coarser scales for less detailed areas.
The system is remarkably robust. It can handle videos with entirely different semantics, tracking changes even in unseen contexts like robot grasping or style-transferred footage, demonstrating a strong generalization capability.
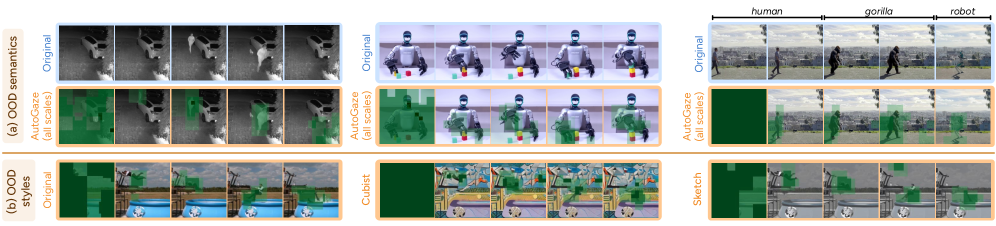 Figure 5: AutoGaze robustly tracks changing parts in videos with out-of-distribution semantics or style transfer, demonstrating strong generalization capabilities.
Figure 5: AutoGaze robustly tracks changing parts in videos with out-of-distribution semantics or style transfer, demonstrating strong generalization capabilities.
Hard Numbers: Performance Boosts
The numbers are compelling. AutoGaze dramatically reduces the visual data burden on downstream AI models.
- Token Reduction: It cuts visual tokens by 4x-100x. That's a massive reduction in the data an MLLM or ViT has to process.
- Speed Boost: Accelerates ViTs and MLLMs by up to 19x. This translates directly to faster real-time processing on hardware.
- High-Res Video: Enables MLLMs to process 1K-frame 4K-resolution videos, a task previously infeasible for many models due to memory constraints.
- Performance Gains: Achieves superior results on video benchmarks, including 67.0% on VideoMME.
- HLVid Benchmark: On the new HLVid benchmark (5-minute 4K videos), an MLLM scaled with AutoGaze improves over the baseline by 10.1% and outperforms the previous best MLLM by 4.5%. This is significant for real-world, long-duration drone operations.
- Gazing Ratio: For 30-FPS, 4K-resolution videos, it needs only around ~1% of patches to achieve a reconstruction loss of 0.7. This is a staggering efficiency.
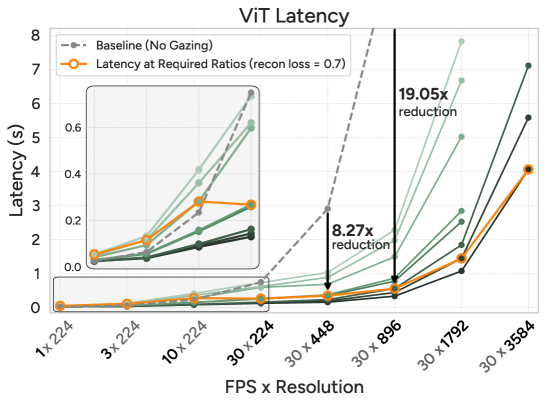 Figure 7: AutoGaze significantly boosts the efficiency of ViTs and MLLMs, reducing latency by up to 19x and 10x respectively, by intelligently selecting fewer patches.
Figure 7: AutoGaze significantly boosts the efficiency of ViTs and MLLMs, reducing latency by up to 19x and 10x respectively, by intelligently selecting fewer patches.
Why This Matters for Your Drone Operations
This isn't just an academic win; it's a practical leap for drone autonomy.
- Extended Endurance & Lighter Payloads: By drastically reducing the computational load, drones can perform complex video analysis with smaller, lighter, and less power-hungry processors. This means longer flight times or the ability to carry more critical sensors.
- Real-time Decision Making: A 19x speedup isn't just a number; it means a drone can process a complex visual scene and make decisions almost instantaneously. Think obstacle avoidance, target tracking, or precision landing in dynamic environments.
- High-Resolution, Long-Duration Missions: Drones can now effectively analyze 4K video streams over extended periods, opening doors for detailed infrastructure inspection, large-scale surveillance, or environmental monitoring where every pixel matters, but only some pixels matter all the time.
- Advanced Autonomy: This capability is foundational for sophisticated AI behaviors. A drone could monitor a wide area, identify an anomaly (e.g., a person falling, as shown in Figure 5), and immediately zoom in or alert an operator, all while maintaining overall situational awareness.
- Search and Rescue: A drone could efficiently scan vast areas, highlighting only what's critical for human review, rather than overwhelming operators with hours of irrelevant footage.
AutoGaze's Current Limits and Future Horizons
While AutoGaze is impressive, it's not a silver bullet.
- Reconstruction Loss Trade-off: The system allows for a user-specified error threshold for video reconstruction. While this is a feature, it also means a choice has to be made. A very low error threshold (perfect reconstruction) would require more patches, reducing the efficiency gains. For critical drone applications, determining the acceptable loss without compromising safety or mission objectives is crucial.
- Generalization to Edge Cases: While Figure 5 shows strong generalization to OOD semantics and style transfer, real-world drone environments are notoriously chaotic. How AutoGaze performs in extreme weather, varied lighting conditions (night vision, fog), or with highly occluded objects would need further validation.
- Hardware Integration: AutoGaze is a software module. Integrating it efficiently onto specific drone
System-on-Chip(SoC) hardware, especially customASICs orFPGAs, would require significant engineering effort to realize maximum power and speed benefits. The current acceleration numbers are forViTsandMLLMsafter AutoGaze, not AutoGaze itself. - Training Data Dependency: Like all AI models, AutoGaze's effectiveness depends on the quality and diversity of its training data, especially for the RL stage. While next-token prediction is general, the specific "gazing sequences" needed for optimal performance in diverse drone tasks (e.g., agricultural analysis vs. package delivery) might require specialized datasets.
DIY Feasibility for Builders and Hobbyists
For the average hobbyist, replicating this exact system from scratch is a significant undertaking. This isn't a simple Python script you can run on a Raspberry Pi today. The underlying MLLMs and ViTs are large, complex models, and training AutoGaze involves substantial computational resources for both the pre-training and reinforcement learning phases.
However, the modular nature of AutoGaze offers hope. If the authors release pre-trained models and efficient inference code, it could become much more accessible. Integrating such a module into existing ROS or PX4 based drone platforms would still require strong programming skills and a good understanding of computer vision pipelines. For now, this is likely research-lab territory, but it points to a future where such intelligent pre-processors are standard features in edge AI frameworks.
The Broader Push for Efficient AI
This paper isn't alone in pushing for more efficient AI. Other researchers are tackling similar problems from different angles. For example, "One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers" explores 'elastic' computation for generative models. Their focus on principled latency-quality trade-offs directly mirrors AutoGaze's goal of adaptive resource management, showing a broader trend towards making complex AI work within tight budgets. Similarly, "EVATok: Adaptive Length Video Tokenization for Efficient Visual Autoregressive Generation" also focuses on optimizing video data representation, albeit for video generation. Their work on adaptive length tokenization to balance reconstruction quality and computational cost is highly complementary, as both papers aim to reduce the data burden before a powerful AI model takes over. Once a drone has efficiently 'gazed' and processed its visual input, it needs to act intelligently. That's where "MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning" comes into play. It provides a framework for how MLLMs can execute complex "visual workflows" based on verified conditions, essentially connecting the efficient perception enabled by AutoGaze to reliable, autonomous decision-making for drones.
The Path to Truly Intelligent Drones
AutoGaze isn't just making MLLMs faster; it's redefining what's possible for drone perception, moving us closer to truly intelligent aerial systems that see with purpose.
Paper Details
Title: Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing Authors: Baifeng Shi, Stephanie Fu, Long Lian, Hanrong Ye, David Eigen, Aaron Reite, Boyi Li, Jan Kautz, Song Han, David M. Chan, Pavlo Molchanov, Trevor Darrell, Hongxu Yin arXiv: 2603.12254 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.