FOMO-3D: Giving Drones 'Super-Vision' for Hidden Hazards
FOMO-3D, a new 3D detection model, uses vision foundation models to drastically improve how drones spot rare and safety-critical objects. This capability is vital for robust autonomous operations, especially in unpredictable environments.

TL;DR: FOMO-3D integrates powerful vision foundation models like OWLv2 and Metric3Dv2 with LiDAR data to dramatically boost a drone's ability to detect obscure and infrequently encountered 3D objects. This approach makes autonomous systems more reliable by addressing the 'long-tail' problem in object recognition.
Giving Drones Eyes for the Unexpected
Autonomous drones excel at navigating familiar environments, avoiding common obstacles like trees or buildings, and tracking predictable objects such as people or vehicles. But what happens when the unexpected appears? A rogue piece of debris, an unusually shaped hazard, or a rare environmental anomaly could spell disaster for a mission. This is the precise challenge a new paper, FOMO-3D, tackles head-on. The research isn't merely about detecting more objects; it’s about equipping drones with a critical advantage in truly unpredictable environments, allowing them to spot the 'unseen' with remarkable precision.
The Problem with Predictable Vision
Current 3D object detection systems, common in drones and other autonomous platforms, are great at identifying frequently encountered objects. They're trained on vast datasets packed with cars, pedestrians, and typical road signs. The real issue emerges with what researchers term the "long tail" of object classes. Consider a construction worker in an unusual pose, a specific piece of discarded industrial equipment, or a unique animal species. These objects appear so infrequently in training data that conventional models often miss them entirely or misclassify them. This isn't just an academic curiosity; it represents a significant safety and reliability gap. For a drone conducting critical infrastructure inspection, search and rescue, or autonomous delivery, overlooking that one unusual but critical hazard can lead to mission failure, damage, or even catastrophic accidents. Relying solely on LiDAR or traditional camera-based methods often falls short, struggling to infer sufficient semantic detail or generalize to novel object shapes without explicit training examples.
How Foundation Models Lend Their Sight
FOMO-3D (Fear Of Missing Out in 3D, a fitting acronym) tackles this by integrating the immense prior knowledge embedded in modern vision foundation models. Specifically, it leverages OWLv2 for its zero-shot 2D object detection and Metric3Dv2 for its monocular depth estimation. These models, trained on colossal datasets, bring a rich understanding of the visual world that goes far beyond what any specific driving or drone dataset could offer.
Stage 1: Generating Multi-modal Proposals
-
Multi-modal Proposal Generation: FOMO-3D starts by casting a wide net. A LiDAR-based branch identifies potential objects using geometric cues. Crucially, a novel camera-based branch leverages
OWLv2to generate 2D proposals. TheseOWLv2proposals aren't just 2D; they're lifted into 3D using depth information fromMetric3Dv2. This allows the system to generate candidate 3D bounding boxes even for objects it has never explicitly seen in 3D training data, simply becauseOWLv2recognizes the object's appearance.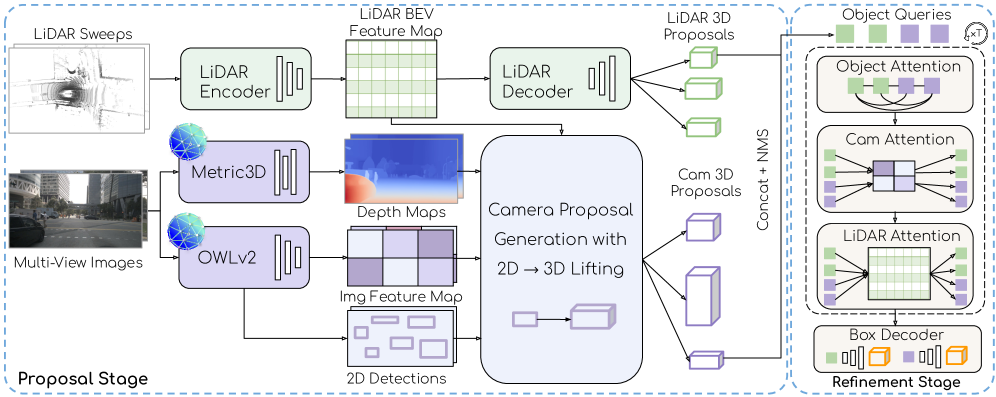 Figure 2: Overview of FOMO-3D, which leverages vision foundation models OWL and Metric3D, and follows a two-stage paradigm with a multi-modal proposal stage and an attention-based refinement stage.
Figure 2: Overview of FOMO-3D, which leverages vision foundation models OWL and Metric3D, and follows a two-stage paradigm with a multi-modal proposal stage and an attention-based refinement stage.
Stage 2: Attention-Based Refinement
-
Attention-Based Refinement: Once initial 3D proposals are generated from both LiDAR and the vision foundation models, the system refines them. This stage employs an attention mechanism that particularly emphasizes the rich image features derived from
OWLv2. This means that even if a LiDAR point cloud is sparse or ambiguous for a rare object, the detailed visual semantics fromOWLv2can help accurately classify and bound the object in 3D. The fusion process carefully unprojects pixels fromOWLv2proposals into 3D usingMetric3Ddepths, then encodes these points into a Bird's Eye View (BEV) feature map, allowingOWLv2tokens to attend to fused LiDAR and image features. This fusion is key to improving generalization for those tricky long-tail classes.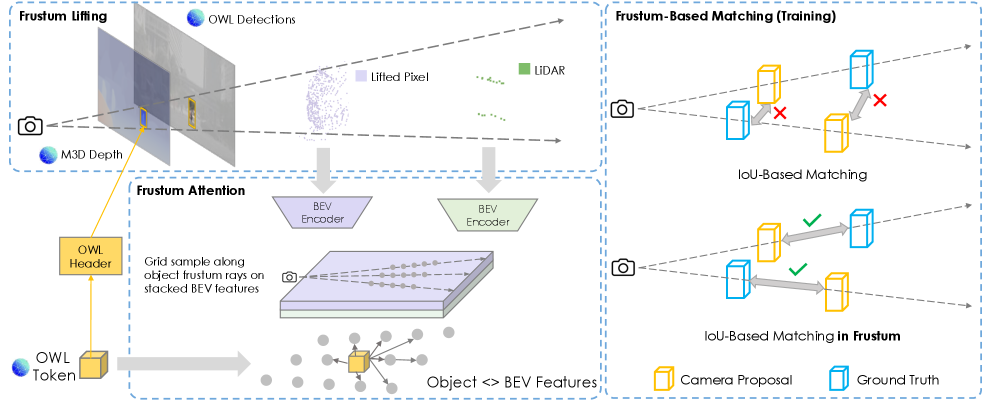 Figure 3: [Left] Lifting OWL camera proposals to 3D bounding boxes. We first unproject pixels inside the camera proposal into 3D using Metric3D depths, and then encode the points into a BEV feature map. Each OWL token subsequently attends to fused LiDAR and image BEV features sampled along the frustum. [Right] During supervision, camera proposals are only matched to ground truth boxes inside the object frustum.
Figure 3: [Left] Lifting OWL camera proposals to 3D bounding boxes. We first unproject pixels inside the camera proposal into 3D using Metric3D depths, and then encode the points into a BEV feature map. Each OWL token subsequently attends to fused LiDAR and image BEV features sampled along the frustum. [Right] During supervision, camera proposals are only matched to ground truth boxes inside the object frustum.
Concrete Gains for the Unseen
FOMO-3D's evaluation results are compelling, particularly given the difficulty of the long-tail problem. Tested on real-world driving data from nuScenes and Highway datasets (which exhibit severe class imbalances, as shown in Figure 4 of the paper), FOMO-3D demonstrates significant gains over LiDAR-only baselines. The data highlights its effectiveness:
- Large Gains on Long-Tail Classes: The model shows substantial improvements in mean Average Precision (mAP) for infrequently appearing objects. For instance, on the
Highwaydataset, FOMO-3D provided+11.0 mAPfor long-tail classes over a strong baseline, and+3.4 mAPoverall. - Improved Generalization: The ability of
OWLv2andMetric3Dv2to generalize from vast internet-scale data directly translates to better detection of novel or rare object instances in 3D, without needing extensive specialized training data for each specific object. - Distance Robustness: The improvements extend across various distance buckets. Figure 5 from the paper illustrates per-class mAP gains, showing that FOMO-3D maintains strong performance for distant objects (e.g., in the
[50, 200]and[200, 230]meter ranges) where camera-based methods often struggle with depth accuracy, and LiDAR can become sparse. - Reduced Misclassifications: As demonstrated in qualitative results (Figure 6), a LiDAR-only model might misclassify a 'child' as an 'adult', or miss a critical, rare object entirely. FOMO-3D, by fusing rich semantic priors, correctly identifies the child and rejects false positives, showcasing superior semantic understanding.
Why This Matters for Drones
This isn't just a win for self-driving cars; it's a significant advancement for drone autonomy. Consider a drone conducting a complex industrial inspection. It needs to identify not just generic equipment, but a specific, rarely seen component with a unique defect signature. Similarly, in search and rescue operations, a drone might need to spot an unusual piece of wreckage or a specific type of distress signal in cluttered environments. FOMO-3D's ability to leverage general visual intelligence to detect these 'unknown unknowns' fundamentally transforms drone capabilities.
This technology could enable drones to:
- Prevent Mission Failures: By spotting unusual hazards (like tangled wires, specific debris, or unique environmental cues) that conventional systems would miss, preventing crashes or operational delays.
- Enhance Inspection Accuracy: Identifying rare defects or specific, hard-to-find components on large structures like bridges, wind turbines, or power lines.
- Improve Search & Rescue: Detecting specific types of debris, unusual human poses, or small, critical items in complex disaster zones.
- Boost Security & Surveillance: Recognizing specific, rarely seen objects or anomalies that could indicate a threat, moving beyond just 'person' or 'vehicle' detection.
True robust autonomy demands handling the unpredictable, and for drones operating in dynamic, unstructured environments, this capability is non-negotiable. FOMO-3D moves drones significantly closer to that reality by giving them 'super-vision' for the unexpected, making them safer and more effective across a multitude of applications.
Real-World Readiness and DIY Feasibility
While the underlying concepts are compelling, replicating FOMO-3D in a hobbyist or even small-scale commercial drone setup today is a significant undertaking. This is advanced research from Waabi, an autonomous vehicle company. The vision foundation models, OWLv2 and Metric3Dv2, are substantial neural networks requiring significant computational resources (GPUs) for inference, let alone training or fine-tuning. Integrating them efficiently with LiDAR data in real-time on a drone's constrained compute platform presents considerable engineering challenges. At present, this work remains firmly in the research and advanced development domain. While the core ideas are open for study via the paper, the specific implementations of OWLv2 and Metric3Dv2 are not readily available for plug-and-play use by hobbyists. This isn't something you'll be flashing onto your Raspberry Pi-powered drone next weekend. However, the trajectory is clear: as these foundation models become more optimized and accessible, and as drone compute power increases, these capabilities will trickle down.
The Broader AI Ecosystem for Drones
FOMO-3D doesn't operate in a vacuum. The field of AI for autonomous systems is rapidly evolving, with several complementary advancements. For instance, while FOMO-3D focuses on what to detect, research in FVG-PT: Adaptive Foreground View-Guided Prompt Tuning for Vision-Language Models explores how to efficiently adapt powerful Vision-Language Models (VLMs) – closely related to the Vision Foundation Models (VFMs) in FOMO-3D – for specific downstream tasks. This could mean fine-tuning a drone's 'super-vision' for a very particular inspection target with minimal data. Furthermore, as drones leverage increasingly complex, often 'black-box' models like those in FOMO-3D for safety-critical operations, understanding why a model made a particular detection decision becomes crucial. This is where work like UNBOX: Unveiling Black-box visual models with Natural-language becomes vital, offering methods for interpreting these sophisticated systems, which is paramount for trust, debugging, and regulatory compliance in advanced drone AI. Finally, detecting an object is only half the battle. Drones operate with continuous data streams, and knowing when to respond is as important as knowing what to respond to. Research like StreamReady: Learning What to Answer and When in Long Streaming Videos addresses this by helping models efficiently process information and react promptly to detected threats or events, ensuring the 'super-vision' from FOMO-3D translates into timely and effective actions. This collective progress points toward increasingly intelligent and reliable autonomous drones, capable of navigating and understanding environments far beyond current expectations. These advanced perception systems are poised to reshape the future of drone applications in unpredictable scenarios.
Paper Details
Title: FOMO-3D: Using Vision Foundation Models for Long-Tailed 3D Object Detection
Authors: Anqi Joyce Yang, James Tu, Nikita Dvornik, Enxu Li, Raquel Urtasun
Published: March 2026 (based on arXiv ID format 2603.08611)
arXiv: 2603.08611 | PDF
Written by
The Flight DeskSharing knowledge about drones and aerial technology.
More from Mini Drone Shop
Stop Wandering: Metacognitive AI Makes Drones Smarter, Not Just Faster

Unmasking the Invisible: Polarization Powers Drone Camouflage Detection

Smarter Drone Comms: AI-Powered Beams Cut Through the Noise
