Adaptive Vision-Language Tuning: Smarter Drones with FVG-PT
FVG-PT enhances vision-language models by improving foreground attention, enabling smarter drone navigation and object detection in real-world environments.

TL;DR: FVG-PT, a new plug-and-play module, addresses visual attention issues in vision-language models like CLIP. By improving focus on foreground objects, it enhances accuracy without sacrificing generalization. This innovation could make drones more efficient in complex scenarios.
Smarter Vision for Smarter Drones
Flying a drone might seem simple, but the underlying technology faces significant challenges: identifying relevant objects amidst visual noise, adapting to new environments without retraining, and maintaining accuracy in dynamic conditions. Enter Foreground View-Guided Prompt Tuning (FVG-PT), a new approach designed to tackle these issues. By improving how vision-language models (VLMs) like CLIP handle foreground attention, FVG-PT helps drones focus on what truly matters in their field of view.
Why Current Approaches Fall Short
Autonomous drones rely heavily on vision systems for tasks such as navigation, object tracking, and obstacle avoidance. However, VLMs often struggle to maintain focus on critical foreground objects during fine-tuning. For instance, a drone might misidentify a moving car as part of the background, leading to errors. While existing techniques like CoOp improve tuning for specific tasks, they frequently sacrifice generalization, leaving models vulnerable in unfamiliar environments.
How FVG-PT Fixes Attention Shifts
FVG-PT introduces a three-part solution to improve foreground attention:
- Foreground Reliability Gate (FRG): Evaluates the reliability of the foreground view and adjusts the model’s focus accordingly.
- Foreground Distillation Compensation (FDC): Uses adapters to guide the model’s attention toward foreground objects during image-text alignment.
- Prior Calibration: Balances the tuned model with its original state to prevent overfitting to foreground elements.
Here’s how it all comes together:
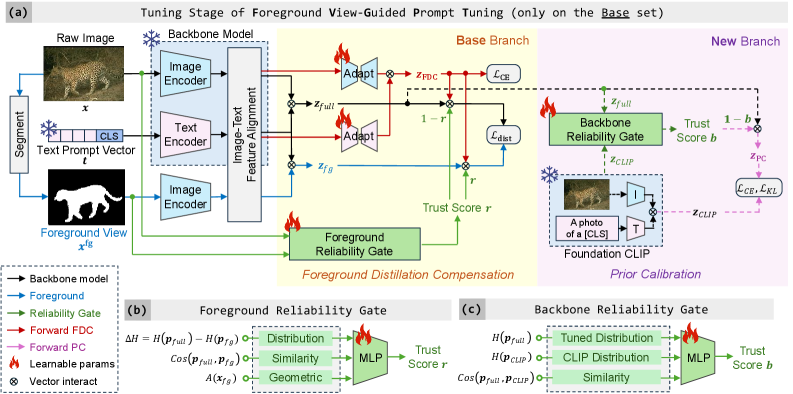 Framework of FVG-PT, showing how components like the Foreground Reliability Gate and Prior Calibration work together.
Framework of FVG-PT, showing how components like the Foreground Reliability Gate and Prior Calibration work together.
What sets FVG-PT apart is its modularity. As a plug-and-play solution, it can be integrated into existing VLMs like CLIP without requiring significant architectural changes.
The Numbers Don’t Lie
FVG-PT’s performance has been validated across multiple datasets and models:
- Accuracy Gains:
- On the Caltech101 dataset, FVG-PT improved foreground attention by 7.9% compared to baseline CLIP.
- For the Flowers102 dataset, the improvement was 6.1%.
- Compatibility: FVG-PT works seamlessly with models like CLIP and CoOp, enhancing results across the board.
- Improved Attention Maps: Visualizations demonstrate that FVG-PT consistently focuses on relevant objects.
 Comparison of attention maps. Baseline CLIP (a) and CoOp (b) often miss key foreground objects, while FVG-PT (c) locks on target.
Comparison of attention maps. Baseline CLIP (a) and CoOp (b) often miss key foreground objects, while FVG-PT (c) locks on target.
Why Drone Engineers Should Care
FVG-PT has the potential to significantly improve drone performance in real-world applications:
- Navigation in Crowded Environments: Drones can better identify obstacles and moving objects, reducing the risk of collisions.
- Search-and-Rescue: Enhanced visual attention enables drones to locate people or objects in challenging conditions, such as dense forests or disaster zones.
- Precision Agriculture: FVG-PT helps drones distinguish between crops and weeds, improving efficiency in agricultural tasks.
- Surveillance and Inspection: With more accurate attention, drones can reliably detect defects or intrusions in industrial settings.
Where FVG-PT Falls Short
While promising, FVG-PT has its limitations:
- Foreground Assumptions: The approach assumes that foreground objects can be clearly separated from the background, which may not hold true in chaotic real-world scenarios.
- Hardware Constraints: The reliance on Grad-CAM for attention maps can be computationally demanding, posing challenges for deployment on edge hardware commonly used in drones.
- Generalization Risks: Although Prior Calibration mitigates overfitting, careful tuning is still required to maintain performance in unseen environments.
- Limited Dataset Scope: The experiments primarily focus on standard datasets like Caltech101, leaving questions about performance on drone-specific benchmarks.
Can You Build It Yourself?
For hobbyist drone builders, implementing FVG-PT is feasible but requires some technical expertise. Here’s what you’ll need:
- Software: Access to the FVG-PT codebase, available on GitHub: https://github.com/JREion/FVG-PT.
- Hardware: A GPU-equipped computer for training, such as NVIDIA Jetson boards for edge deployment.
- Data: Labeled datasets relevant to your use case, such as aerial images for navigation or object detection.
- Skills: Familiarity with VLMs like CLIP, Python frameworks (e.g., PyTorch), and fine-tuning techniques.
While the technology is accessible, scaling it for fully autonomous drones will require further optimization for onboard computation.
Related Work to Know
FVG-PT is part of a broader effort to improve vision-language models. Other notable research includes:
- FOMO-3D: Explores vision foundation models for long-tailed 3D object detection, potentially complementing FVG-PT in enhancing drone vision systems (arXiv link).
- Scale Space Diffusion: Focuses on processing noisy data, which could benefit drones operating in dynamic environments (arXiv link).
- UNBOX: Investigates interpretable visual models, aligning with FVG-PT’s emphasis on trustworthiness in decision-making (arXiv link).
These studies highlight complementary approaches to advancing drone autonomy and robustness.
Final Thoughts
Foreground View-Guided Prompt Tuning offers a practical and modular solution for improving vision-language models, making them smarter and more reliable. For drones, this could mean the difference between adequate navigation and exceptional task execution. The real challenge now is adapting this technology for real-world rotorcraft.
Paper Details
Title: FVG-PT: Adaptive Foreground View-Guided Prompt Tuning for Vision-Language Models
Authors: Haoyang Li, Liang Wang, Siyu Zhou, Jiacheng Sun, Jing Jiang, Chao Wang, Guodong Long, Yan Peng
Published: N/A
arXiv: 2603.08708 | PDF
Related Papers
- FOMO-3D: Using Vision Foundation Models for Long-Tailed 3D Object Detection (arXiv link)
- Scale Space Diffusion: Processing Noisy Data in Dynamic Environments (arXiv link)
- UNBOX: Unveiling Black-box Visual Models with Natural Language (arXiv link)
Figures Available
- Total: 10
Written by
The Flight DeskSharing knowledge about drones and aerial technology.
More from Mini Drone Shop
Stop Wandering: Metacognitive AI Makes Drones Smarter, Not Just Faster

Unmasking the Invisible: Polarization Powers Drone Camouflage Detection

Smarter Drone Comms: AI-Powered Beams Cut Through the Noise
