VoxelHound: 360° Semantic World Modeling for Autonomous Drones
New research introduces VoxelHound, a multimodal perception system that enables robots to build a panoramic, semantic 3D understanding of their environment, compensating for motion jitter and fusing data from RGB, thermal, polarization cameras, and LiDAR.
TL;DR: Researchers have developed a new dataset and perception system, VoxelHound, which allows quadruped robots to build a 360-degree semantic understanding of their environment using multiple sensors. This system effectively fuses visual (RGB, thermal, polarization) and LiDAR data, even compensating for robot movement, to predict navigable space and identify objects with high accuracy.
Drones are getting smarter, but truly understanding their environment, beyond just avoiding obstacles, remains a significant hurdle. A new perception framework, VoxelHound, initially proven on quadruped robots, allows systems to deeply understand their 360-degree surroundings. It identifies obstacles semantically and maps out fully traversable 3D space, even in challenging conditions.
Why Current Drone Vision Falls Short
Current autonomous perception systems, especially those relying heavily on RGB cameras, often fall short in complex, real-world scenarios. They struggle with low light, fog, glare, or environments where objects blend into the background. Most existing "occupancy prediction" methods are designed for stable, wheeled vehicles, making them ill-suited for the dynamic, often jarring movements of a legged robot – or indeed, a drone. Such limitations lead to inconsistent spatial reasoning and unreliable navigation in the very environments where autonomous systems are most needed: cluttered, unpredictable, and sometimes poorly lit spaces.
VoxelHound: Building a Complete 360-Degree World Model
The core of this work lies in two main innovations: the PanoMMOcc dataset and the VoxelHound perception framework. The PanoMMOcc dataset is a first-of-its-kind, real-world collection of panoramic multimodal data specifically for quadruped robots. It gathers synchronized streams from RGB, thermal, and polarization cameras, alongside LiDAR point clouds, across diverse outdoor and indoor scenes.
 Figure 1: While existing solutions often rely on vehicle-mounted platforms, this approach is designed for agile, mobile robots.
Figure 1: While existing solutions often rely on vehicle-mounted platforms, this approach is designed for agile, mobile robots.
This multimodal input proves critical. RGB provides rich color and texture, thermal sensors see through darkness and fog by detecting heat signatures, and polarization cameras offer unique material properties and glare reduction. LiDAR, naturally, provides precise 3D geometry regardless of lighting.
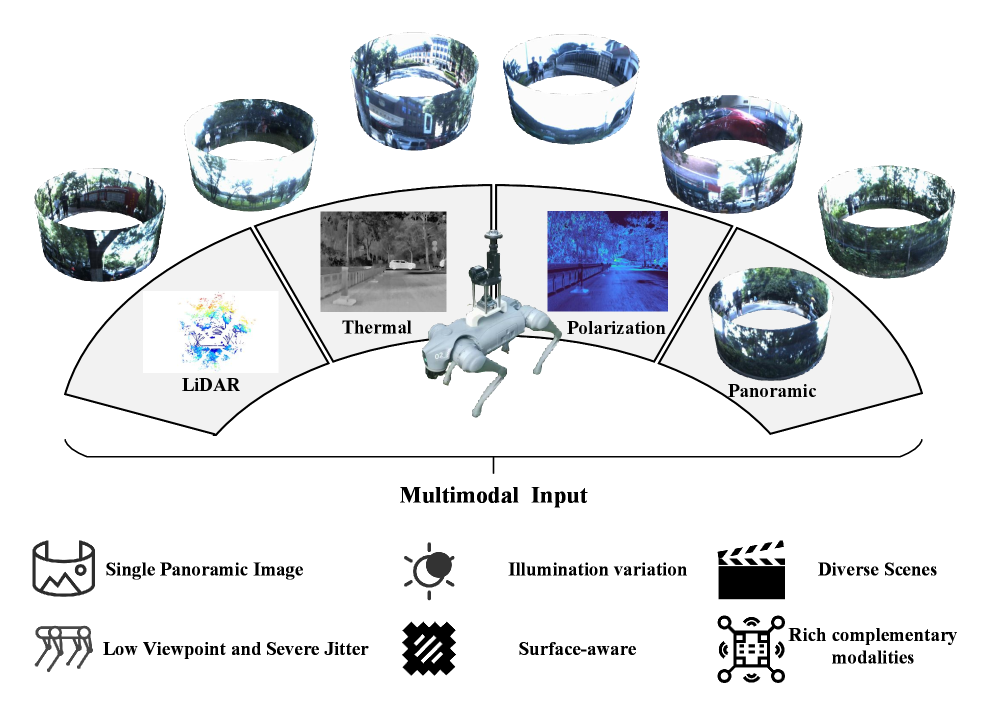 Figure 2: The research leverages a quadruped platform, which presents unique challenges for stable perception compared to wheeled vehicles.
Figure 2: The research leverages a quadruped platform, which presents unique challenges for stable perception compared to wheeled vehicles.
The VoxelHound framework processes these disparate data streams. It features a Vertical Jitter Compensation (VJC) module, crucial for mobile platforms. This module actively mitigates the severe viewpoint perturbations caused by the robot's body pitch and roll during movement. Without VJC, the constantly shifting camera perspective would introduce significant distortions, making consistent spatial reasoning nearly impossible. By stabilizing the perception, VJC ensures the system can build a coherent 3D map.
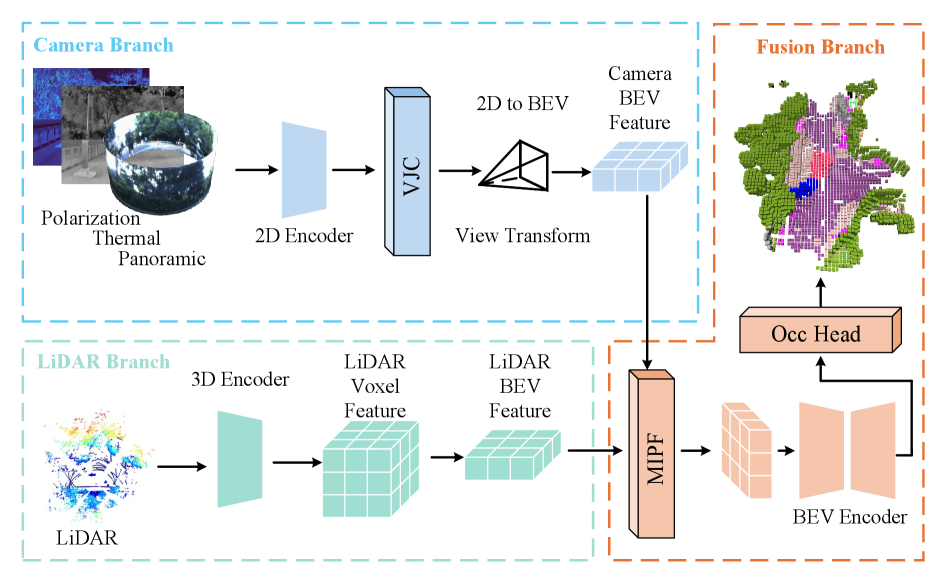 Figure 6: VoxelHound's architecture showing distinct encoders for each modality (RGB, thermal, polarization, LiDAR) before fusing them into a Bird's-Eye-View (BEV) space.
Figure 6: VoxelHound's architecture showing distinct encoders for each modality (RGB, thermal, polarization, LiDAR) before fusing them into a Bird's-Eye-View (BEV) space.
Following this, a Multimodal Information Prompt Fusion (MIPF) module takes over. The module intelligently combines the processed features from all modalities. Instead of simply concatenating data, MIPF uses "prompts" – essentially, learned guidance signals – to focus the fusion on relevant information from each sensor, enhancing the volumetric occupancy prediction. This combined leverage of panoramic visual cues and auxiliary modalities allows the system to build a semantically rich 3D map of the environment, identifying not just occupied space but what occupies it (e.g., "tree," "person," "road").
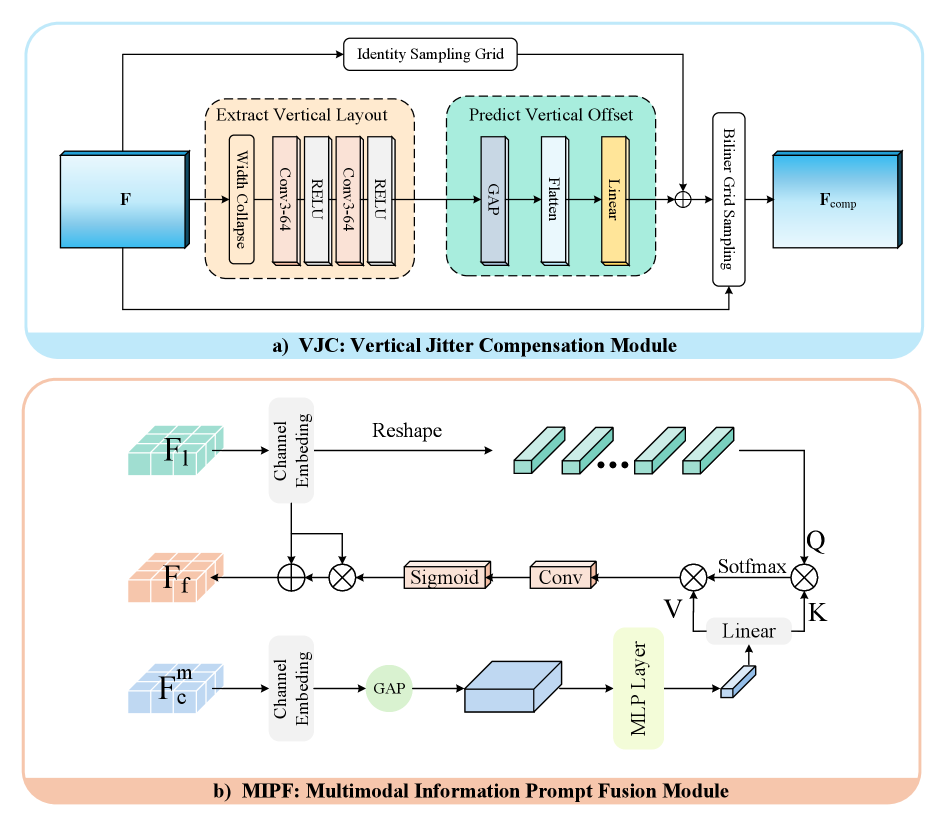 Figure 7: A closer look at the VJC module, which stabilizes input despite robot movement, and the MIPF module, which intelligently combines sensor data.
Figure 7: A closer look at the VJC module, which stabilizes input despite robot movement, and the MIPF module, which intelligently combines sensor data.
VoxelHound's Quantifiable Edge in Environmental Understanding
The VoxelHound framework delivered impressive performance. Tested on the new PanoMMOcc dataset, it achieved state-of-the-art results for panoramic multimodal semantic occupancy prediction.
- Significant Improvement:
VoxelHoundoutperformed existing methods, showing a +4.16% improvement inmIoU(mean Intersection over Union). This metric strongly indicates how accurately the system predicts both occupied space and the semantic categories of objects within that space. - Robustness: Qualitative comparisons demonstrated that
VoxelHoundgenerated "more coherent occupancy structures and more consistent semantic predictions" even under challenging conditions like overexposed daytime, nighttime, and complex rural scenes. - Multimodal Advantage: Ablation studies in the paper confirm that integrating thermal and polarization data, alongside RGB and LiDAR, significantly boosts performance, particularly in adverse lighting or visually ambiguous situations.
A 4% jump in mIoU for a complex task like semantic occupancy prediction is substantial, pointing to a genuinely more reliable system.
Why VoxelHound Matters for Autonomous Drones
While demonstrated on quadruped robots, the principles behind VoxelHound are directly transferable to drones, especially those designed for complex autonomous tasks.
- Enhanced Navigation & Safety: Drones could gain an unparalleled 360-degree understanding of their surroundings, far beyond simple obstacle avoidance. A delivery drone could navigate a dense urban canyon or a forest at night, not just dodging branches but identifying them as "trees" and understanding the navigable air corridors.
- All-Weather, All-Light Operations: The multimodal approach ensures drones aren't crippled by low light, heavy fog, rain, or glare. Thermal vision penetrates darkness, and polarization helps cut through reflections, vastly expanding operational windows for inspection, search and rescue, or surveillance.
- Intelligent Interaction: Semantic understanding allows for more intelligent mission planning. Drones could identify specific objects of interest (e.g., "damaged power line," "person in distress") within their 3D occupancy map, enabling targeted actions rather than just generic exploration.
- Precision Delivery & Inspection: For drone delivery, knowing the precise "free space" on a porch or balcony for a package drop-off becomes much more reliable. For industrial inspection, differentiating between a pipe, a structural beam, and a temporary obstruction proves crucial for automated analysis.
- Foundation for Advanced AI: This granular, semantic 3D understanding provides a rich foundation for higher-level AI to make more informed decisions, predict future states, and interact more intelligently with the world.
The Road Ahead: Challenges for VoxelHound
No system is perfect, and VoxelHound, while impressive, faces current boundaries.
- Hardware Complexity: The reliance on four distinct sensing modalities (RGB, thermal, polarization cameras, and LiDAR) means a heavier, more power-hungry, and more expensive sensor payload. For mini-drones, size, weight, and power (SWaP) constraints are paramount. Integrating all these sensors into a compact, lightweight drone package capable of reasonable flight times presents a significant engineering challenge.
- Computational Overhead: Processing synchronized panoramic data from four modalities, especially with the
VJCandMIPFmodules, demands substantial computational resources. This might push beyond the capabilities of current edge AI processors commonly found in smaller, power-constrained drones, potentially requiring off-board processing or heavier on-board compute. - Calibration Complexity: Aligning and calibrating multiple panoramic sensors (especially with polarization) accurately across a moving platform is non-trivial. The authors provide calibration tools, but maintaining this precision in real-world, dynamic drone operations would be a continuous challenge.
- Dynamic Environments: While robust against robot jitter, the paper doesn't deeply explore performance in highly dynamic environments with fast-moving obstacles or rapidly changing scenes, which a drone frequently encounters. The semantic categories are also finite; classifying novel or unusual objects might still be a challenge.
Can You Build Your Own VoxelHound?
Replicating VoxelHound as a hobbyist would be a substantial undertaking, but not entirely impossible with significant dedication and resources.
- Hardware: Acquiring the necessary multimodal sensor suite (panoramic RGB, thermal, polarization cameras, and a compact LiDAR unit) would be costly, easily running into thousands of dollars. Integrating them, ensuring precise synchronization, and physically mounting them on a drone platform requires significant mechanical and electrical engineering skills.
- Software: The authors plan to publicly release the dataset (
PanoMMOcc) and code, which is a huge boon. This means the core algorithms and trained models might be accessible. However, adapting the framework from a quadruped to a drone, configuring it for specific drone flight controllers, and optimizing it for lightweight edge computing would require advanced programming and machine learning expertise. - Calibration: The provided calibration tools will be essential, but mastering multi-sensor calibration for a custom setup is a steep learning curve.
In short, while the code and data being open-source is fantastic for researchers, a casual hobbyist might find the hardware and integration barrier too high. A well-resourced academic lab or a dedicated startup would be the more likely candidate for direct replication and adaptation.
Beyond VoxelHound: Towards Persistent World Models
This research lays a critical foundation for a drone's perception, but it's just one piece of the puzzle. Beyond understanding its immediate 360-degree surroundings, a truly autonomous drone needs to remember and predict. For instance, the paper "Towards Spatio-Temporal World Scene Graph Generation from Monocular Videos" by Peddi et al. explores how to build a persistent, relational 'scene graph' of the world. Consider VoxelHound providing a drone its current understanding, and then a system like Peddi's building a long-term memory of how objects interact and evolve, even when they're temporarily out of sight. Such capabilities move beyond instantaneous perception to true world modeling.
Another crucial aspect is understanding how the world changes even when the drone isn't directly observing it. "Out of Sight, Out of Mind? Evaluating State Evolution in Video World Models" by Ma et al. directly addresses this, assessing how well world models can track 'state evolution' for unobserved elements. For a drone relying on VoxelHound to build its initial understanding, this kind of predictive capability would be vital for safer and smarter navigation, allowing it to anticipate changes in its environment.
Finally, even with advanced perception, how does the drone's own AI interpret its own motion within this rich visual context? "Geometry-Guided Camera Motion Understanding in VideoLLMs" by Feng et al. delves into how higher-level AI (specifically VideoLLMs) can better interpret the drone's own camera motion. For a drone relying on extensive visual data for semantic understanding, ensuring its AI accurately processes its own movement within the visual context, informed by a VoxelHound-like perception, is vital for coherent decision-making and robust autonomy.
This work pushes autonomous perception forward, offering a clear path to drones that truly understand their world, even when conditions are far from ideal.
Paper Details
Title: Panoramic Multimodal Semantic Occupancy Prediction for Quadruped Robots Authors: Guoqiang Zhao, Zhe Yang, Sheng Wu, Fei Teng, Mengfei Duan, Yuanfan Zheng, Kai Luo, Kailun Yang Published: March 2026 arXiv: 2603.13108 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.