VLA Deep Dive: Unpacking How AI Drones Actually See and Act
A new study peers inside Vision-Language-Action (VLA) models, revealing that visual perception overwhelmingly drives robot behavior, often overriding language commands, and exposing spatially bound motor programs.
TL;DR: New research dissects Vision-Language-Action (VLA) models, finding that their visual pathway overwhelmingly dictates robot actions, often making language prompts secondary. These "AI brains" frequently rely on spatially fixed motor programs, meaning they learn to target specific coordinates rather than abstract task goals.
Peeling Back the AI's Layers
For anyone building or flying autonomous drones, understanding why your AI makes a certain decision is critical. We've seen significant advancements in Vision-Language-Action (VLA) models, which aim to bring human-like understanding and execution to robotics. But until now, these models have largely been black boxes. This new paper from Bryce Grant, Xijia Zhao, and Peng Wang peels back the curtain, offering a rare mechanistic look inside these complex AI systems. Their findings reveal what truly drives action, and it's not always what you'd expect.
The Black Box Problem in Autonomous Systems
VLAs hold immense promise: a single AI architecture capable of perceiving its environment, understanding natural language commands, and executing physical actions. For drones, this means everything from autonomous inspection with specific instructions to complex manipulation tasks in hazardous environments. However, the current reality is that these models are often opaque. When a drone fails a task, is it a vision problem, a language misinterpretation, or a motor control error? Without understanding the internal workings, debugging becomes guesswork, and developing truly robust, predictable autonomous systems remains a challenge. This lack of transparency limits our ability to build next-generation, high-assurance drone platforms.
Dissecting the VLA Brain: A New Approach
The researchers didn't just test performance; they delved into the "brains" of six different VLA models, ranging from 80 million to 7 billion parameters. Their approach is sophisticated, blending three key techniques. First, activation injection enabled them to "hot-swap" internal signals. By recording activations from a successful task and then injecting them into a null-prompt scenario, they could causally link specific internal states to observed behaviors.
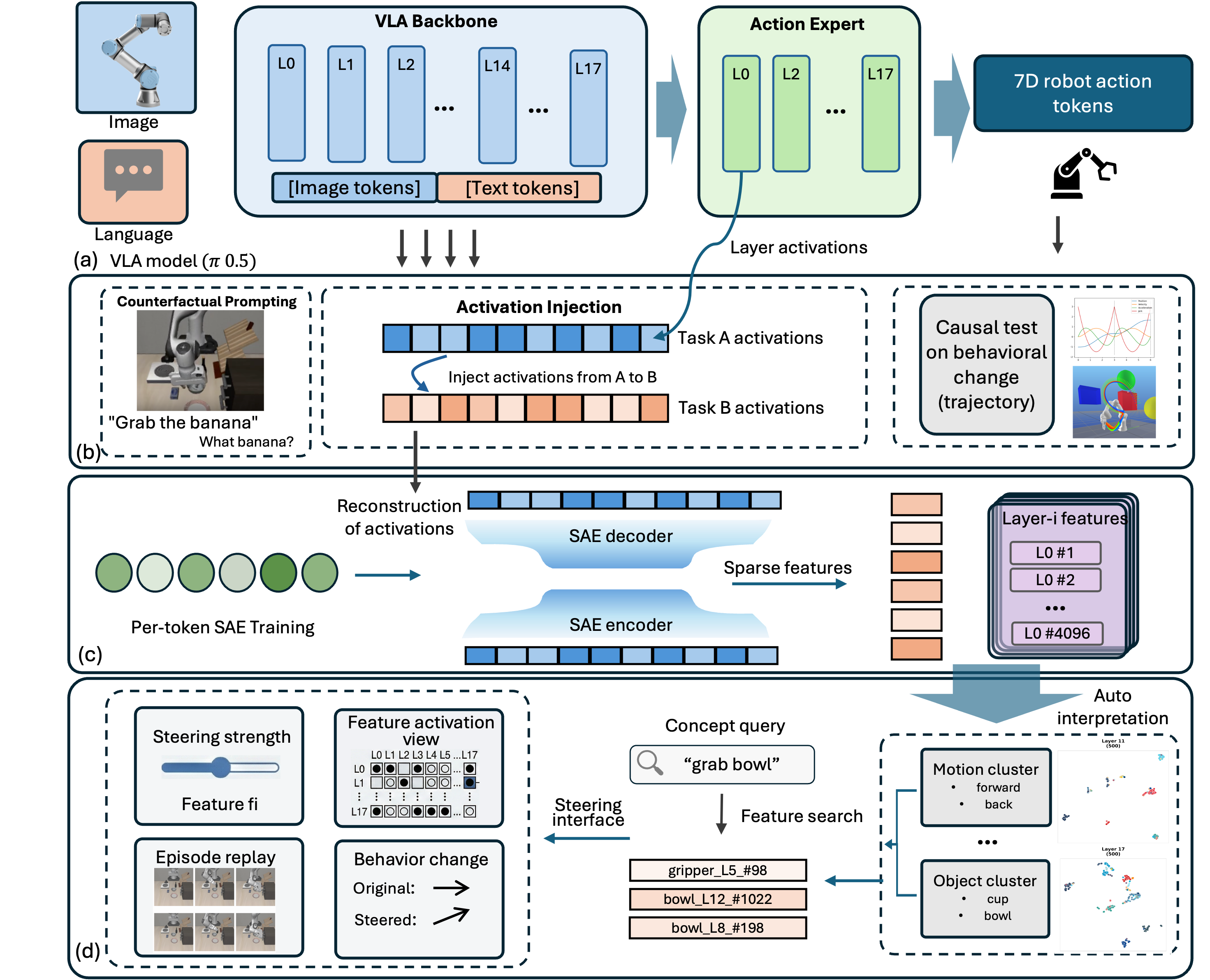 Figure 2: Methodology overview. Top: activations are recorded from VLA backbone and action expert layers during rollout episodes, then replayed under counterfactual conditions (null prompts, cross-task scenes) to establish causal relationships via behavioral change. Middle: per-token SAEs decompose layer activations into sparse features. Bottom: features are clustered, searched, and causally validated through ablation and steering experiments, with results visualized in Action Atlas.
Figure 2: Methodology overview. Top: activations are recorded from VLA backbone and action expert layers during rollout episodes, then replayed under counterfactual conditions (null prompts, cross-task scenes) to establish causal relationships via behavioral change. Middle: per-token SAEs decompose layer activations into sparse features. Bottom: features are clustered, searched, and causally validated through ablation and steering experiments, with results visualized in Action Atlas.
Second, they employed Sparse Autoencoders (SAEs) to decompose complex layer activations into sparse, interpretable features. This is akin to breaking down a blurry image into its sharpest, most meaningful components. This enabled them to identify discrete "concepts" within the model's internal representations. Finally, linear probes identified what specific parts of the model encode, such as goal semantics or motor programs. The team then validated these findings through causal ablation, selectively turning off identified features to observe the behavioral impact. All these findings are publicly explorable through their Action Atlas tool.
What Really Drives the Actions: Key Findings
The findings are direct and have significant implications for drone autonomy:
- Vision Overrides Language: Across all architectures, the visual pathway was overwhelmingly dominant. Injecting baseline visual activations into episodes with null prompts (meaning no language instruction) recovered near-identical behavior. For
π0.5, injecting just a single layer (L0) recovered99.7%of the original behavior. This highlights that what the VLA sees is often far more critical than what it's told.
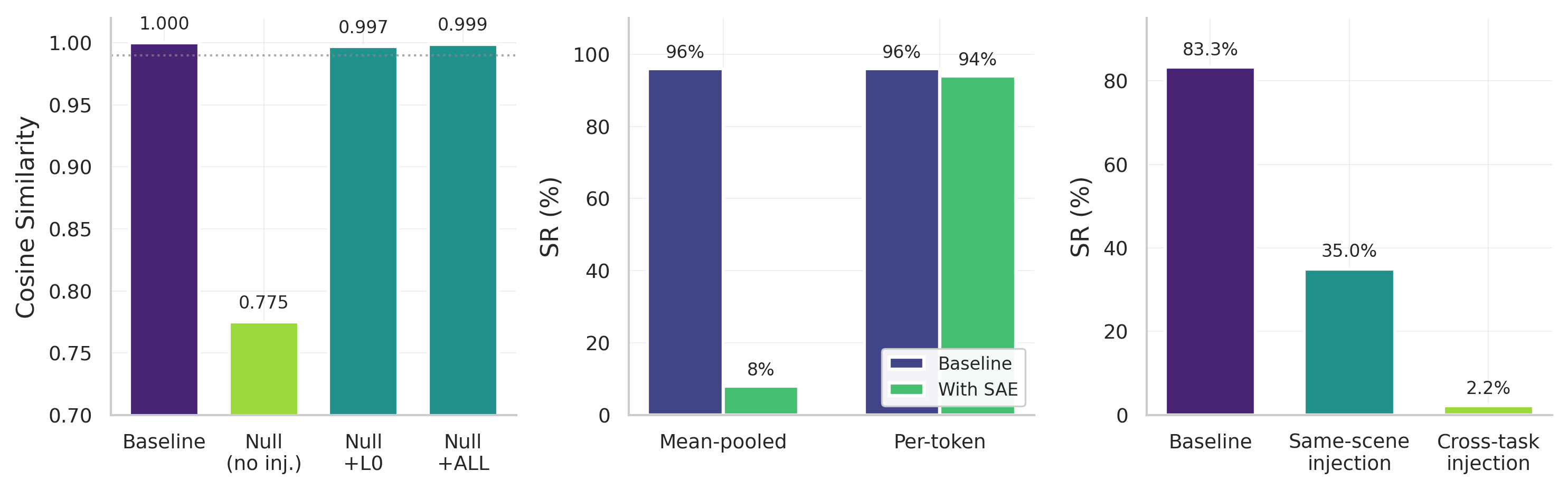 Figure 1: Three core findings on π0.5\pi_{0.5}. Left: Activation injection recovers baseline behavior from null-prompt episodes. Without injection, null prompts drop cosine similarity to 0.775; injecting a single layer (L0) recovers 0.997 and all layers recovers 0.999, demonstrating visual pathway dominance. Middle: Per-token SAE processing is essential. Mean-pooled SAE reconstruction destroys task success (96%→\to8%) despite high explained variance, while per-token processing preserves performance (96%→\to94%). Right: Cross-task injection fails destination tasks (83.3%→\to2.2%) and same-scene injection partially succeeds (35.0%), confirming spatially bound motor programs. These patterns replicate across all six models (Table 6).
Figure 1: Three core findings on π0.5\pi_{0.5}. Left: Activation injection recovers baseline behavior from null-prompt episodes. Without injection, null prompts drop cosine similarity to 0.775; injecting a single layer (L0) recovers 0.997 and all layers recovers 0.999, demonstrating visual pathway dominance. Middle: Per-token SAE processing is essential. Mean-pooled SAE reconstruction destroys task success (96%→\to8%) despite high explained variance, while per-token processing preserves performance (96%→\to94%). Right: Cross-task injection fails destination tasks (83.3%→\to2.2%) and same-scene injection partially succeeds (35.0%), confirming spatially bound motor programs. These patterns replicate across all six models (Table 6).
- Spatially Bound Motor Programs: When they injected activations from one task (e.g., picking up a red block) into a different task in the same scene (e.g., picking up a blue block), the robot frequently reverted to the source-task position.
99.8%ofX-VLAepisodes aligned with the source trajectory. This indicated the VLA learned "go to these coordinates" rather than "go to the object with this property," suggesting a reliance on spatially fixed motor programs rather than abstract task representations.
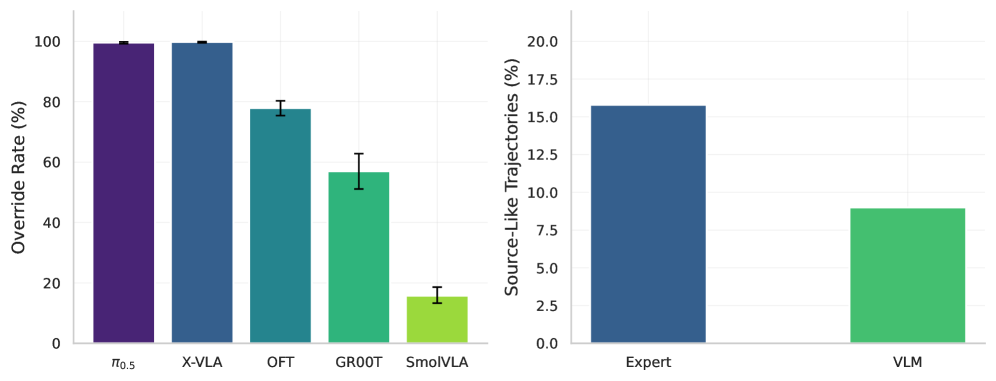 Figure 3: Cross-task displacement override rates. Left: override rate across five models. π0.5\pi_{0.5} (99.6%, n=1,968n{=}1{}968) and X-VLA (99.8%, n=3,150n{=}3{}150) show near-complete source behavior transfer; OFT 77.9% (n=1,079n{=}1{}079); GR00T 57.0% (n=270n{=}270, suite-dependent: goal 85.6%, long 33.3%). Error bars: 95% Wilson CIs. Right: SmolVLA pathway displacement (15.8% expert vs. 9.0% VLM, 732 pairs).
Figure 3: Cross-task displacement override rates. Left: override rate across five models. π0.5\pi_{0.5} (99.6%, n=1,968n{=}1{}968) and X-VLA (99.8%, n=3,150n{=}3{}150) show near-complete source behavior transfer; OFT 77.9% (n=1,079n{=}1{}079); GR00T 57.0% (n=270n{=}270, suite-dependent: goal 85.6%, long 33.3%). Error bars: 95% Wilson CIs. Right: SmolVLA pathway displacement (15.8% expert vs. 9.0% VLM, 732 pairs).
- Language Sensitivity Varies: Language isn't universally ignored. Its importance depends heavily on task structure. When visual context uniquely specifies the task (e.g., only one object to interact with), language is frequently disregarded. However, when multiple goals share a scene (e.g., "pick up the red block" when red and blue blocks are present), language becomes essential. For the
libero_goalbenchmark, performance dropped from94%to10%with wrong prompts, whereaslibero_objecttasks showed60-100%success regardless of prompt.
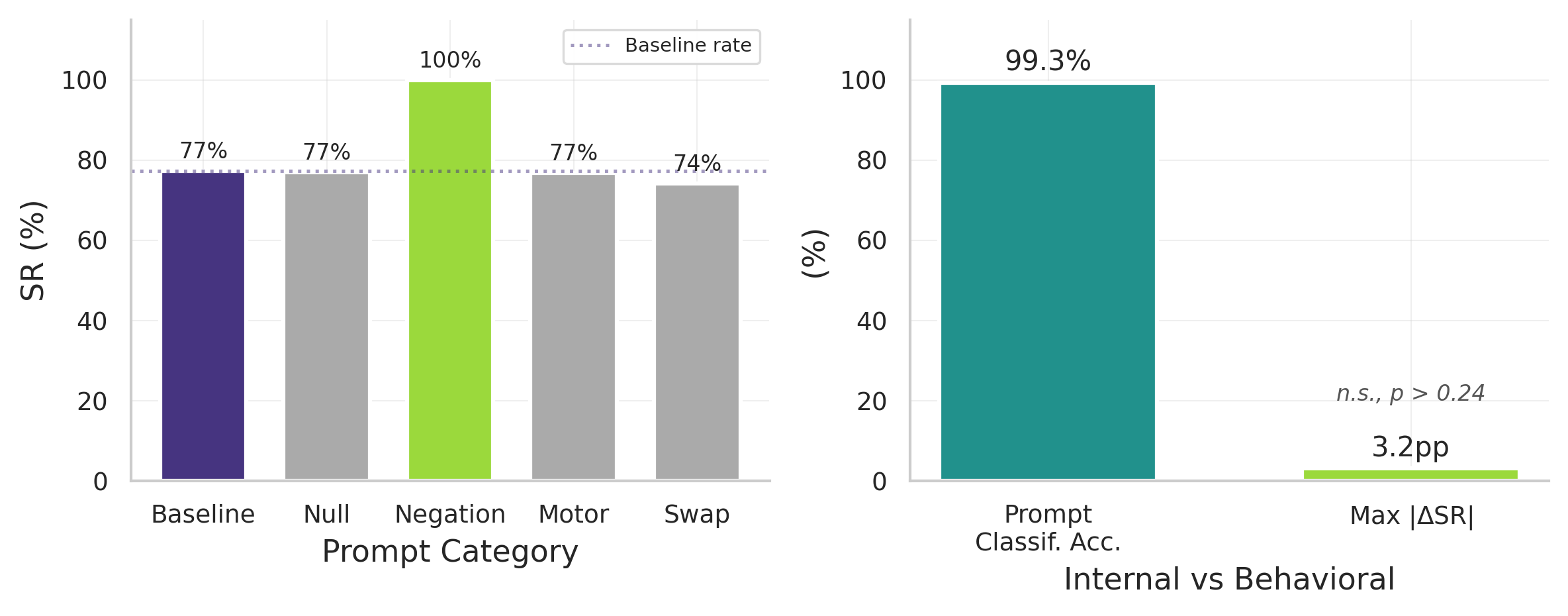 Figure 10: Language is ignored despite internal distinction. Left: counterfactual prompting across 3,396+ episodes shows no significant behavioral difference (p>>0.24). Right: layer 17 classifiers distinguish prompts with 99.3% accuracy, yet behavior is unchanged.
Figure 10: Language is ignored despite internal distinction. Left: counterfactual prompting across 3,396+ episodes shows no significant behavioral difference (p>>0.24). Right: layer 17 classifiers distinguish prompts with 99.3% accuracy, yet behavior is unchanged.
-
Specialized Pathways: In multi-pathway architectures like
π0.5,SmolVLA, andGR00T,expert pathwaysencode motor programs, whileVLM pathwaysencode goal semantics. Expert injection led to2xgreater behavioral displacement, confirming these pathways occupy separable activation subspaces. -
Concept Identification and Ablation: The researchers contrastively identified
82+manipulation concepts. Causal ablation revealed sensitivity ranging from28-92%zero-effect rates. This implies that while some concepts are critical (like "put" or "open"), many features can be removed without affecting behavior, independent of the representation width.
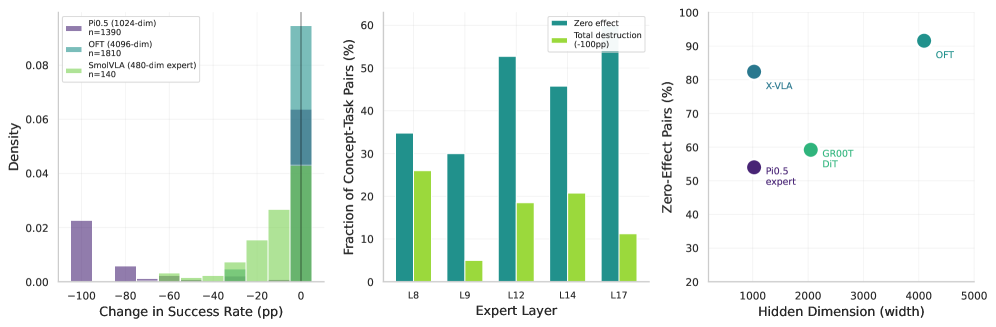 Figure 4: Concept ablation causal sensitivity across five models. Each bar shows the fraction of concept-task pairs with zero effect (gray), partial effect (blue), and total destruction (−100-100pp, red) under single-feature ablation. SmolVLA (480-dim expert) is the most sensitive at 28% zero-effect rate; OFT (4096-dim) and X-VLA (1024-dim) are the most resilient at 92% and 82% respectively. Causal sensitivity does not follow representation width: X-VLA approaches OFT despite sharing π0.5\pi_{0.5}’s 1024-dim hidden size.
Figure 4: Concept ablation causal sensitivity across five models. Each bar shows the fraction of concept-task pairs with zero effect (gray), partial effect (blue), and total destruction (−100-100pp, red) under single-feature ablation. SmolVLA (480-dim expert) is the most sensitive at 28% zero-effect rate; OFT (4096-dim) and X-VLA (1024-dim) are the most resilient at 92% and 82% respectively. Causal sensitivity does not follow representation width: X-VLA approaches OFT despite sharing π0.5\pi_{0.5}’s 1024-dim hidden size.
 Figure 5: PUT concept ablation (L8): “Put the cream cheese in the bowl.” Top (green): Baseline. The robot picks up the cream cheese and places it in the bowl (91 steps). Bottom (red): With PUT features zeroed at layer 8, the robot drops the cream cheese into the bowl, knocking it over (300 steps, task failure).
Figure 5: PUT concept ablation (L8): “Put the cream cheese in the bowl.” Top (green): Baseline. The robot picks up the cream cheese and places it in the bowl (91 steps). Bottom (red): With PUT features zeroed at layer 8, the robot drops the cream cheese into the bowl, knocking it over (300 steps, task failure).
Why This Matters for Autonomous Drones
This isn't just academic curiosity; these findings directly impact how we design and deploy autonomous drones:
- Designing Robust Control Systems: Knowing that vision is paramount means investing more in robust, high-fidelity visual perception for drones. If your drone's VLA relies heavily on what it sees, ensuring its cameras and vision processing are top-notch becomes crucial.
- Clarifying Language Commands: The task-dependent nature of language sensitivity suggests that for drone missions with ambiguous visual cues (e.g., multiple similar targets), language instructions must be precise and unambiguous. For tasks where the visual context is unique, overly verbose commands might simply be ignored.
- Predictable Behavior for Safety: Understanding that VLAs can learn spatially bound motor programs rather than abstract task goals is crucial. A drone might "learn" to fly to a specific GPS coordinate where a package was previously dropped, rather than learning the generalized concept of "drop package at designated zone." This highlights a potential failure mode: assuming generalization where it isn't present. For safety-critical operations, this calls for rigorous testing across varied environments.
- Debugging and Diagnostics: If a drone misbehaves, this research provides a framework for diagnosis. Is it a visual occlusion issue? A misidentified object? Or did the language instruction get lost in translation because the visual context was too strong? This framework moves us beyond guesswork.
- Specialized Drone Architectures: For drones with manipulator arms or complex payloads, the discovery of separate "expert" pathways for motor control and "VLM" pathways for goal semantics could inform modular AI designs. These pathways could potentially be optimized independently for better performance or lower computational load.
Limitations & What's Next
While illuminating, this study has a few points to consider for real-world drone applications:
- Lab-Controlled Environments: The experiments were conducted in simulated environments (
Libero,MetaWorld,SimplerEnv) or controlled lab settings. Real-world drone operations face dynamic lighting, weather, unpredictable obstacles, and varying textures that can significantly impact visual perception. - Focus on Manipulation: The tasks primarily involve robotic arm manipulation. While the underlying VLA principles apply, direct insights into drone flight control (e.g., altitude hold, obstacle avoidance during high-speed flight) are inferred rather than directly observed.
- Generalization of Concepts: The high
28-92%zero-effect rates for concept ablation suggest that many identified features might be redundant or not universally critical. This could mean current SAEs aren't perfectly isolating concepts, or that VLAs have a lot of "dead weight" in their internal representations that doesn't causally affect behavior. - Temporal Dynamics: Initial findings on temporal ablation effects in
π0.5were found to be an artifact (Figure 9). Understanding when certain features or pathways are most active during a task could be vital for dynamic drone missions, and this area needs further exploration. - Hardware and Power Constraints: The models tested range up to 7 billion parameters. Deploying such large models on resource-constrained mini-drones still presents significant challenges in terms of computational power, weight, and battery life.
Diving Deeper: DIY Feasibility
For the average drone hobbyist, replicating this research from scratch is a significant undertaking. The computational resources required to train and deeply probe 7-billion-parameter VLA models are substantial, typically requiring powerful GPU clusters. However, the researchers have released Action Atlas (https://action-atlas.com), an interactive tool that allows anyone to explore VLA representations across these six models. For advanced builders and researchers, some of the models like π0.5, SmolVLA, and GR00T are open-source, providing a foundation for deeper experimentation, assuming access to robust hardware like NVIDIA Jetson platforms or cloud GPUs. This isn't a weekend project, but it opens the door for serious exploration.
The Broader AI Landscape
This mechanistic study doesn't stand alone. Understanding how VLAs operate internally is complemented by work addressing related challenges in AI for robotics. For instance, "Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding" by Wu et al. highlights how Multimodal Large Language Models (MLLMs)—close cousins to VLAs—improve their 3D spatial understanding. This is directly relevant; a drone's ability to act precisely hinges on its perception of 3D space, enhancing the very "vision" component this paper finds so dominant. Meanwhile, the paper "LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs" by Tao et al. reminds us that alongside dissecting VLA internals, robust benchmarks are also needed for their real-world performance, especially for long-duration drone missions where context and consistency are paramount. And for truly fine-grained interaction, "DreamPartGen: Semantically Grounded Part-Level 3D Generation via Collaborative Latent Denoising" by Yu et al. shows how AIs learn to understand objects at a functional, part-level – a foundational capability that will be crucial for a VLA-powered drone performing intricate assembly or repair tasks.
Building Smarter Drones
This research offers a critical step beyond black-box AI, providing a clearer picture of what truly drives autonomous decision-making. For the future of autonomous drones, this mechanistic understanding is the bedrock for building truly intelligent, reliable systems that we can trust.
Paper Details
Title: Not All Features Are Created Equal: A Mechanistic Study of Vision-Language-Action Models Authors: Bryce Grant, Xijia Zhao, Peng Wang Published: March 2026 arXiv: 2603.19233 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.