VEGA-3D: Giving Drones Intuitive 3D Sense from Video Models
VEGA-3D introduces a framework letting AI infer robust 3D structural priors from video generation models. This significantly enhances spatial reasoning for autonomous systems like drones, all without explicit 3D training data.
TL;DR: AI models often struggle with true 3D spatial understanding. This paper shows how to extract implicit 3D knowledge from video generation models, effectively giving AI a 'latent world simulator' to improve geometric reasoning for drones and other autonomous agents without needing specific 3D data or sensors.
Unleashing Spatial Instincts in Autonomous Systems
For drones, understanding the world isn't just about spotting objects; it's about grasping their position, depth, and how they interact in a dynamic 3D environment. This new paper, "Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding," marks a significant stride toward achieving that deeper understanding. It shows how AI can tap into an inherent spatial intelligence, allowing future drones to navigate and interact with environments with enhanced geometric reasoning, all without being explicitly taught 3D.
The Blurry Vision of Current AI
Multimodal Large Language Models (MLLMs) are powerful for semantic understanding—they know what things are. But ask them to reason about where something is in 3D space, or how it moves, and they often fall short. They suffer from what the authors call "spatial blindness." Current fixes are cumbersome: relying on dedicated 3D sensors like LiDAR or depth cameras, or demanding extensive, explicit 3D datasets for training. These approaches are bottlenecked by data scarcity, high computational costs, and the added weight and power draw of extra hardware on a drone. We need solutions that are lightweight, power-efficient, and generalize well, which current methods rarely do.
Tapping into a Latent World
The core idea behind VEGA-3D (Video Extracted Generative Awareness) is innovative: what if large-scale video generation models already contain robust 3D structural priors? To generate coherent video, these models must inherently understand how objects move and exist in 3D space. VEGA-3D repurposes a pre-trained video diffusion model as a "Latent World Simulator." Instead of training from scratch on explicit 3D data, it extracts spatiotemporal features from the intermediate noise levels of these generative models.
VEGA-3D then integrates these extracted features, rich in geometric cues, with the MLLM's semantic representations using a clever "token-level adaptive gated fusion mechanism." Think of it as giving the MLLM a direct feed of intuitive 3D understanding, complementing its semantic knowledge. This means dense geometric awareness without the need for additional 3D sensors or explicit 3D supervision.
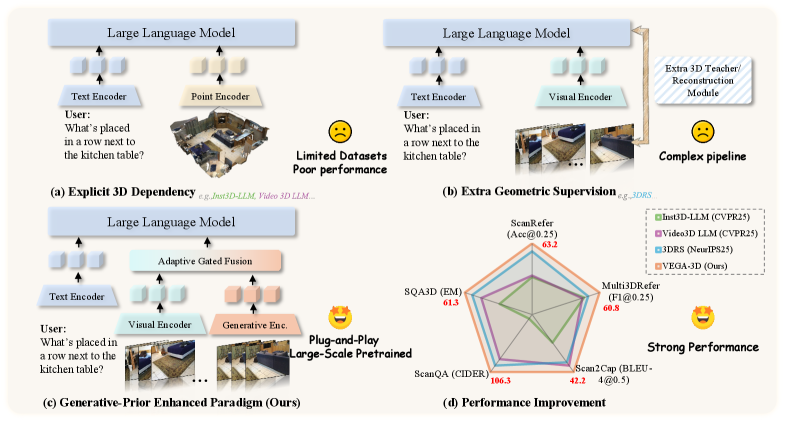 Figure 1: Unlike methods relying on (a) explicit 3D inputs or (b) complex geometric supervision, (c) our VEGA-3D extracts implicit priors from video generation models. By repurposing them as Latent World Simulators, we achieve (d) superior performance without external 3D dependencies.
Figure 1: Unlike methods relying on (a) explicit 3D inputs or (b) complex geometric supervision, (c) our VEGA-3D extracts implicit priors from video generation models. By repurposing them as Latent World Simulators, we achieve (d) superior performance without external 3D dependencies.
The authors demonstrate that these generative models indeed "know space." Figure 2 shows strong multi-view geometric consistency—meaning the model understands an object from different angles, a hallmark of true 3D awareness.
 Figure 2: The generation model demonstrates strong multi-view geometric consistency, evidenced by high correspondence scores and stable PCA feature representations across shifting camera views. By leveraging these priors, our VEGA-3D overcomes the spatial ambiguity observed in the baseline, yielding precisely-located attention maps of the target object in the instruction.
Figure 2: The generation model demonstrates strong multi-view geometric consistency, evidenced by high correspondence scores and stable PCA feature representations across shifting camera views. By leveraging these priors, our VEGA-3D overcomes the spatial ambiguity observed in the baseline, yielding precisely-located attention maps of the target object in the instruction.
This isn't just a conceptual leap; it's a practical architectural improvement. The framework (Figure 4) acts as a plug-and-play addition, enhancing existing MLLMs.
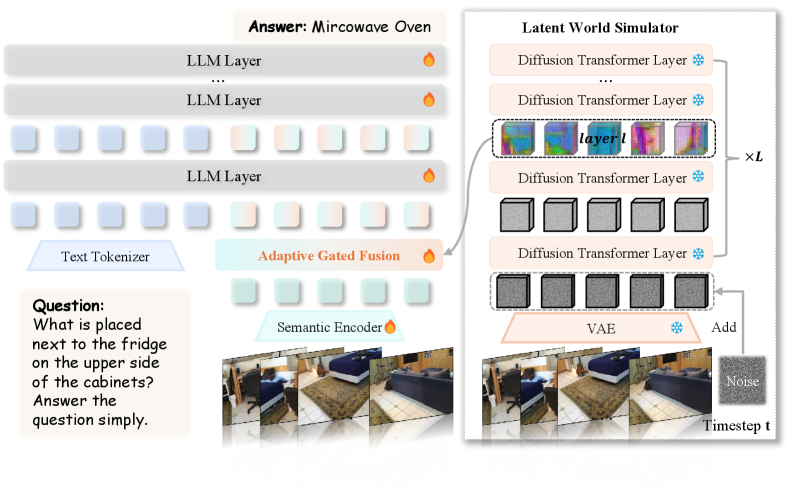 Figure 4: Overview of the VEGA-3D framework. We repurpose a frozen video generation model as a Latent World Simulator to extract implicit 3D priors. These features are dynamically integrated with the semantic stream via Adaptive Gated Fusion, equipping the MLLM with dense 3D structural awareness.
Figure 4: Overview of the VEGA-3D framework. We repurpose a frozen video generation model as a Latent World Simulator to extract implicit 3D priors. These features are dynamically integrated with the semantic stream via Adaptive Gated Fusion, equipping the MLLM with dense 3D structural awareness.
Hard Numbers: Performance That Matters
VEGA-3D isn't just elegant; it performs. Across various 3D scene understanding, spatial reasoning, and embodied manipulation benchmarks, it consistently outperforms state-of-the-art baselines. For instance:
- ScanRefer: VEGA-3D shows significantly improved accuracy in localizing referred objects in cluttered 3D scenes, outperforming baselines by several points. This means a drone could pinpoint a specific
toolon a workbench even if it's partially hidden. - VSI-Bench (Appearance Order): The model better captures the temporal ordering of object appearances, crucial for understanding sequences of events in a video feed.
- Generalization: The approach demonstrates superior generalization, indicating that the implicit priors are robust and applicable to novel scenarios without re-training on explicit 3D data. The authors also show that performance peaks at intermediate noise levels and specific intermediate layers of the DiT (Diffusion Transformer) model, suggesting a sweet spot for extracting these geometric cues.
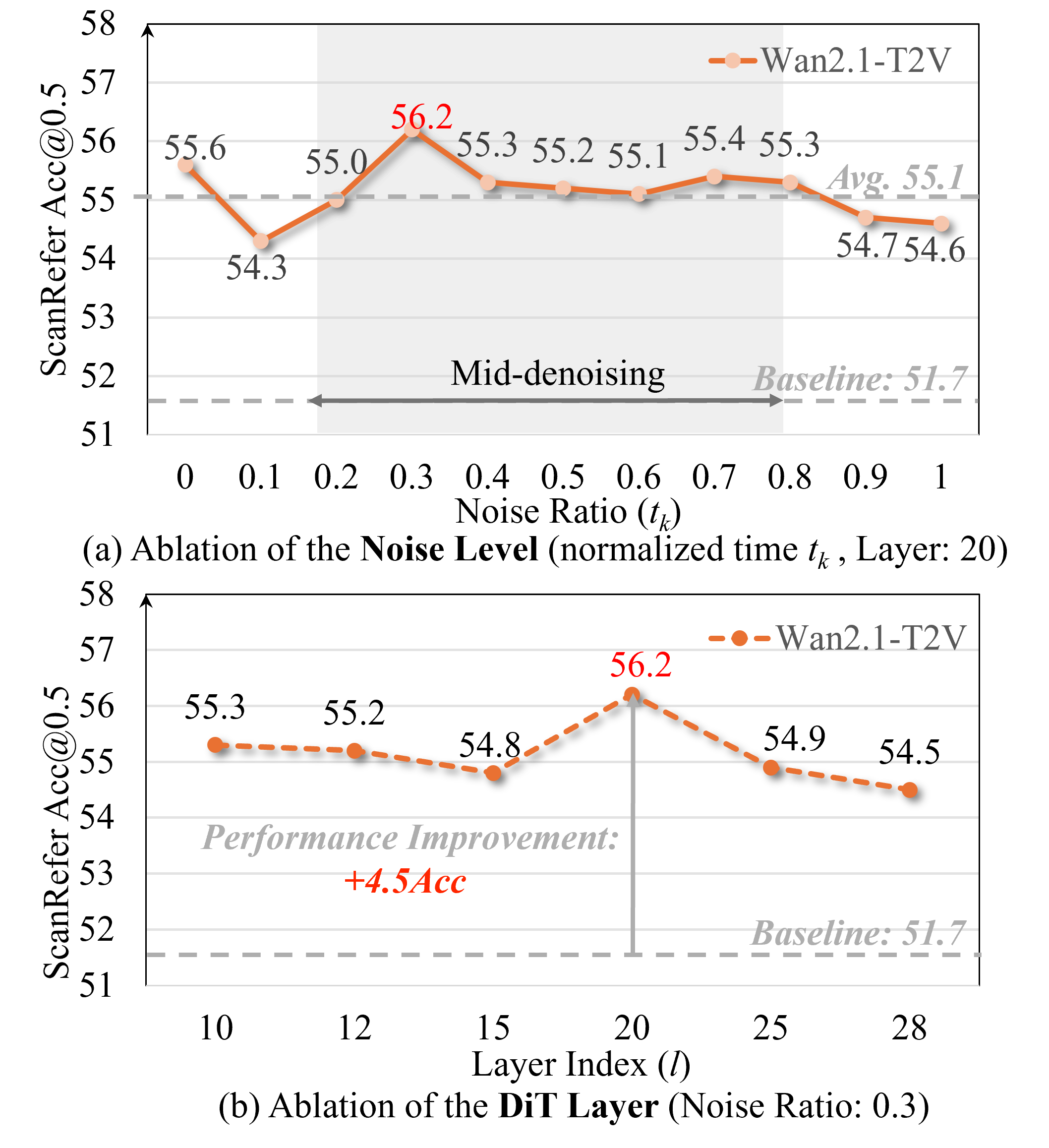 Figure 6: Ablation studies on noise injection and DiT depth. (a) Performance peaks at intermediate noise levels. (b) Specific intermediate layers capture the most robust geometric cues.
Figure 6: Ablation studies on noise injection and DiT depth. (a) Performance peaks at intermediate noise levels. (b) Specific intermediate layers capture the most robust geometric cues.
Crucially, the inference overhead is manageable. VEGA-3D caches the Wan2.1-T2V features once per scene, making subsequent queries fast. This matters for real-time drone applications.
Why This Matters for Drones
This is a big deal for autonomous drones. Consider a drone that doesn't just object detect a landing pad, but truly understands its 3D geometry, its relation to surrounding obstacles, and even how wind might affect its approach angle based on observed physical dynamics. This research enables:
- Advanced Navigation & SLAM: More robust
Simultaneous Localization and Mapping (SLAM)in complex, previously unseen environments, even without relying solely onLiDARorstereo cameras. - Intelligent Interaction: Drones capable of fine-grained manipulation, like picking up specific items or performing intricate repairs, because they understand the spatial relationships of components.
- Enhanced Situational Awareness: Better understanding of dynamic scenes, predicting movement paths of other objects or people, leading to safer and more efficient operations.
- Reduced Hardware Burden: Potentially less reliance on heavy, power-hungry 3D sensors, allowing for lighter, longer-flying, and more affordable drones. This could democratize advanced autonomy for hobbyists and smaller commercial operations.
- Embodied AI: Drones that don't just execute commands but truly comprehend their physical environment, making more intelligent, context-aware decisions.
Limitations & What's Missing
While promising, this isn't a magic bullet:
- Fine-grained Disambiguation: The authors acknowledge (Figure 9) that while VEGA-3D captures reasonable spatial anchors, it can still struggle with very fine-grained instance disambiguation in extremely cluttered scenes. Identifying the exact bolt among many identical ones might still be a challenge.
- Real-time Constraints: While inference overhead is reduced by caching features, the initial extraction from a video generation model could still be computationally intensive for extremely fast, real-time decision-making on low-power drone hardware. Optimization for
edge AIdeployment will be critical. - Environmental Generalization: The training data for video generation models often comes from diverse but curated datasets. Real-world drone environments can be highly unpredictable, with extreme lighting, weather, and unique object types. Further testing in adverse conditions is necessary.
- Scalability to Novel Physics: While the models implicitly learn physical laws, how well this scales to truly novel or complex physical interactions (e.g., fluid dynamics, soft body physics) remains to be seen. For specific drone tasks, explicit physics models might still be required.
Is This for the DIY Builder?
Yes and no. The good news is that the authors have made the code publicly available on GitHub. This means hobbyists and researchers can experiment with the framework. However, running large video diffusion models requires substantial computational resources, likely a powerful GPU (e.g., NVIDIA A100 or RTX 4090). Integrating this into a custom drone project would involve interfacing with ROS or a similar drone operating system, and managing the computational load. It's not a plug-and-play module for a Raspberry Pi-powered quadcopter today, but it lays the groundwork for future, more efficient implementations that could be. The beauty is that it leverages existing generative models, so the barrier isn't training a huge model from scratch.
This work complements other advancements in AI perception. For instance, while VEGA-3D focuses on geometric understanding, papers like "Under One Sun: Multi-Object Generative Perception of Materials and Illumination" by Yoshii et al. show how drones could perceive the properties of objects—their materials and how they're lit—adding another crucial layer of intelligence. Similarly, "DreamPartGen: Semantically Grounded Part-Level 3D Generation via Collaborative Latent Denoising" by Yu et al. delves into how AI can comprehend and even generate 3D objects based on their meaningful parts, allowing a drone to understand a car's wheels, doors, and engine as distinct, functional components. All these pieces contribute to a drone that doesn't just navigate, but truly understands its world. For ensuring these sophisticated models actually work in the real world, benchmarks like "LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs" by Tao et al. are vital, pushing for rigorous testing of these advanced AI systems in long-duration, real-world scenarios.
Ultimately, VEGA-3D represents a smart shortcut to equipping drones with a deeper, more intuitive understanding of the 3D world, moving us closer to truly intelligent autonomous systems that don't just react, but comprehend.
Paper Details
Title: Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding Authors: Xianjin Wu, Dingkang Liang, Tianrui Feng, Kui Xia, Yumeng Zhang, Xiaofan Li, Xiao Tan, Xiang Bai Published: March 2026 (arXiv preprint) arXiv: 2603.19235 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.