Teaching Drones to Think Spatially: Precision AI for 3D Editing
Large Language Models often struggle with precise 3D spatial understanding. This research introduces `3D-Layout-R1`, a structured reasoning framework that enables Vision-Language Models to perform fine-grained spatial layout editing from natural language, significantly boosting precision and control.
TL;DR: Large Language Models (LLMs) and Vision-Language Models (VLMs) struggle with accurate 3D spatial reasoning. This paper introduces
3D-Layout-R1, a structured reasoning framework that uses scene graphs to enable VLMs to precisely edit 3D layouts based on natural language instructions, significantly improving spatial coherence and reducing errors.
Unlocking Spatial Intelligence for Drones
For drone operators, the dream of telling a UAV, "Sort those components by size on the assembly line," or "Move the heavy battery pack to the center of the charging station," and watching it comply, remains just out of reach. Current AI, even advanced LLMs, often falters when it comes to understanding the nuanced spatial relationships in a 3D environment and acting on those insights with precision. This research brings us a significant step closer to drones that don't just perceive, but intelligently edit their physical surroundings based on your spoken commands.
The Spatial Reasoning Gap in Current AI
The impressive linguistic prowess of LLMs and VLMs has transformed how we interact with AI. They can summarize, generate text, and even describe complex images. However, their spatial understanding, particularly for fine-grained 3D manipulation, has been a persistent Achilles' heel. When asked to rearrange objects in a room or sort items on a workbench, these models often produce logically inconsistent layouts, objects that overlap, or ignore critical spatial constraints. This isn't just an inconvenience; for drones performing sensitive tasks like construction, logistics, or delicate inspection, imprecise spatial reasoning means mission failure, potential damage, or even safety hazards. The core limitation has been the lack of a structured, interpretable way for these models to reason about spatial relationships in a consistent manner. Unlike humans who intuitively grasp object permanence and physical constraints, current large language and vision models often rely on statistical correlations from vast datasets. This approach, while powerful for language generation, falls short when precise geometric understanding and adherence to physical laws are paramount. They lack an inherent, explicit model of 3D space, making fine-grained manipulation a significant hurdle.
How Structured Reasoning Delivers Precision
The 3D-Layout-R1 framework tackles this by introducing a Structured Reasoning approach built around scene-graph reasoning. Instead of relying on ambiguous free-form thinking paths, the model operates by updating a structured scene graph. Think of a scene graph as a blueprint of the environment: it explicitly defines objects, their properties (size, shape, position), and, crucially, their relationships to each other (e.g., "box A is next to box B," "tool C is on the workbench"). This isn't just a semantic trick; it's a fundamental shift. By representing the world as a network of interconnected objects and their attributes, the model gains a robust, symbolic understanding of the environment. This structured representation allows for logical inference and constraint checking that free-form text generation simply cannot provide, ensuring that spatial edits are not only accurate but also physically plausible.
 Conceptual diagram of the Structured Reasoning framework, showing natural language instruction and an initial scene graph leading to structured reasoning and an updated scene graph.
Conceptual diagram of the Structured Reasoning framework, showing natural language instruction and an initial scene graph leading to structured reasoning and an updated scene graph.
Given a natural language instruction, the model doesn't just guess; it reasons over this existing scene graph. This reasoning process generates an updated scene graph that reflects the instruction while ensuring spatial coherence – meaning objects don't magically pass through each other or end up in impossible positions. The authors explicitly guide this reasoning through structured relational representations, enhancing both interpretability and control. This explicit guidance is key. Instead of a black box, you get a clear trace of how the model arrived at its spatial decisions.
The training pipeline for 3D-Layout-R1 is also noteworthy. It leverages a Vision-Language Model to predict these step-by-step layout edits, optimizing its rollouts using a combination of rewards. These rewards aren't just about getting the objects somewhere; they specifically penalize collisions, reward proper object placement (IoU for overlap), and ensure the output is in the correct format, reinforcing the structured nature of the reasoning.
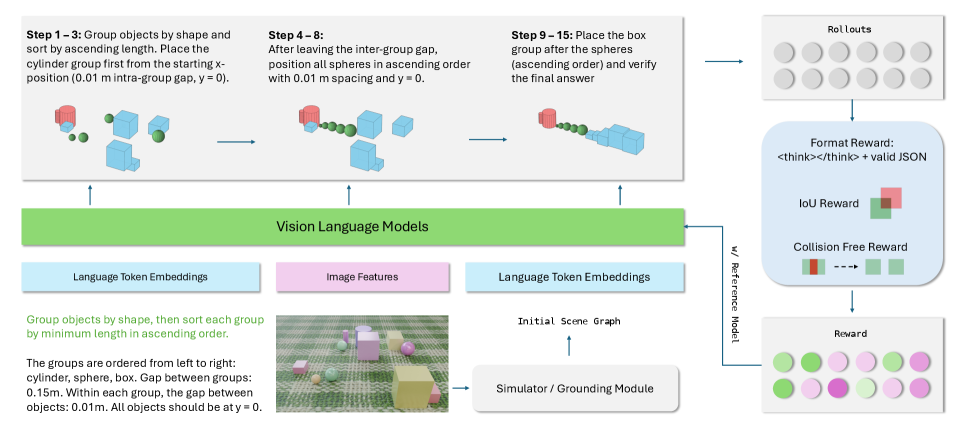 Figure 3: Overview of our training pipeline. The vision-language model predicts step-by-step layout edits from the instruction and initial scene graph, and rollouts are optimized using a combination of format, IoU, and collision-free rewards.
Figure 3: Overview of our training pipeline. The vision-language model predicts step-by-step layout edits from the instruction and initial scene graph, and rollouts are optimized using a combination of format, IoU, and collision-free rewards.
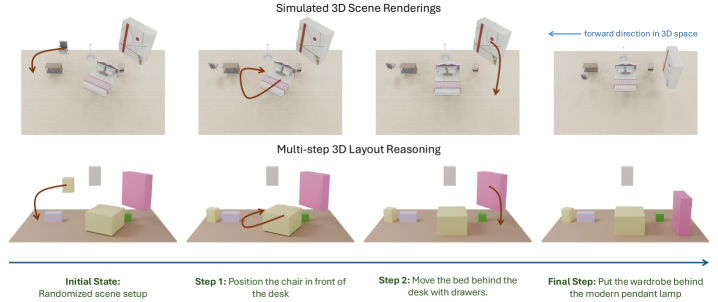
This structured approach allows the model to handle complex instructions that involve multiple spatial constraints, as demonstrated in room layout reasoning, where it can interpret and validate distances between objects.
 Figure 4: Example of text-guided 3D room layout reasoning, showing how the model interprets constraints to update object poses step by step and validate distances.
Figure 4: Example of text-guided 3D room layout reasoning, showing how the model interprets constraints to update object poses step by step and validate distances.
The framework isn't limited to synthetic environments either. It's been tested in warehouse simulations and even real-world tabletop rearrangement tasks, hinting at practical applicability.
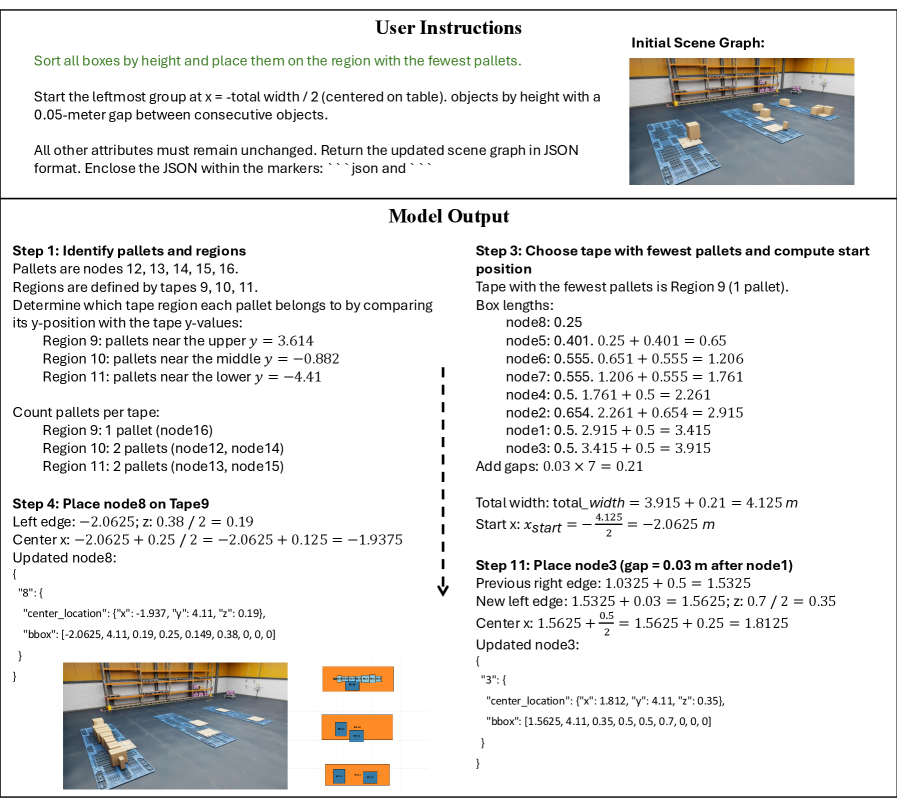 Figure 5: Out-of-domain warehouse simulation results showing our model correctly following user instructions with 3D boxes.
Figure 5: Out-of-domain warehouse simulation results showing our model correctly following user instructions with 3D boxes.
 Figure 6: Real-world tabletop rearrangement and pick-and-place task.
Figure 6: Real-world tabletop rearrangement and pick-and-place task.
Hard Numbers: Performance That Matters
The numbers speak for themselves. The Structured Reasoning framework significantly outperforms existing methods:
- 15% improvement in
IoU(Intersection over Union): This means objects are placed much more accurately, with better overlap with their intended final positions. - 25% reduction in center-distance error: Objects end up closer to their target coordinates.
- Up to 20% higher
mIoUcompared to SOTA zero-shot LLMs: This is a direct win against the best general-purpose models, showing specialized spatial reasoning is crucial.
These gains were consistent across various model scales, from 1.7B to 8B parameters, indicating that the benefits of structured reasoning aren't just a fluke of model size.
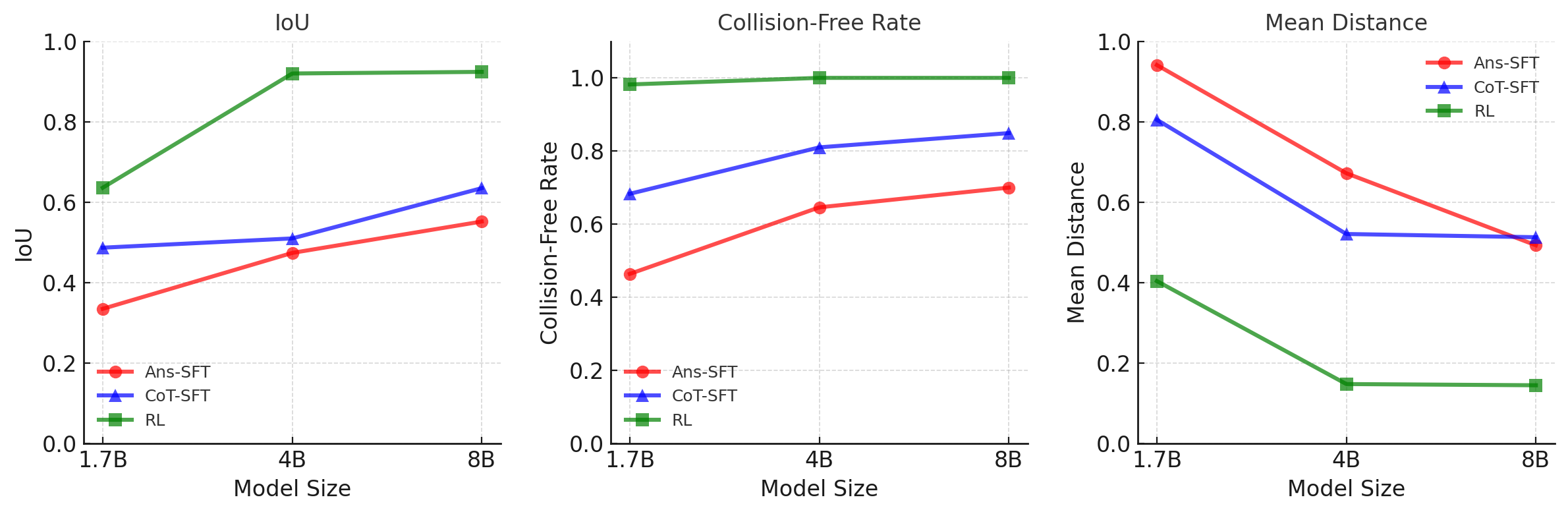 Figure 8: Scaling behavior on the Sorting benchmark. Reasoning-based training improves performance consistently across all model scales (1.7B–8B).
Figure 8: Scaling behavior on the Sorting benchmark. Reasoning-based training improves performance consistently across all model scales (1.7B–8B).
Qualitative comparisons further underscore the advantage. While models like Qwen3-235B and DeepSeek often fail to follow instructions accurately, leading to collisions or misplaced objects, 3D-Layout-R1 consistently matches the desired ground truth. This isn't just about minor inaccuracies; it's about fundamental task completion.
 Figure 9: Qualitative comparison of sorting and spatial alignment tasks: Qwen3-235B and DeepSeek often fail to follow the instructions and produce collisions/overlaps, while our method matches the ground truth.
Figure 9: Qualitative comparison of sorting and spatial alignment tasks: Qwen3-235B and DeepSeek often fail to follow the instructions and produce collisions/overlaps, while our method matches the ground truth.
Why This Matters for Drones
This research marks a significant step for drone autonomy and interaction. A drone equipped with a manipulator arm could achieve:
- Automated Logistics: Rearranging packages in a warehouse or sorting components on an assembly line based on spoken instructions.
- Search and Rescue: A drone identifying and moving debris to access a trapped individual, following a command like "Clear the path to the red backpack."
- Complex Assembly: Assisting in construction by placing specific modules or tools precisely where needed, guided by a foreman's natural language.
- Environmental Monitoring/Maintenance: A drone repositioning sensors or making minor repairs by physically interacting with its environment based on high-level directives.
The ability to translate natural language into precise 3D spatial edits means drones can become more intelligent, versatile, and user-friendly tools, moving beyond simple observation to active, intelligent manipulation of their surroundings. This unlocks a new level of human-robot collaboration in dynamic environments.
Limitations & What's Still Missing
While 3D-Layout-R1 shows impressive gains, it's important to be realistic about its current stage.
- Scene Graph Generation: The paper assumes an input
scene graph. In a truly real-world, unknown environment, a drone would first need to generate an accuratescene graphfrom raw sensor data (LiDAR, cameras). This is a non-trivial problem in itself and isn't directly addressed here. - Dynamic Environments: The current evaluation focuses on static environments. Real-world drone operations often involve moving objects, people, or changing conditions, which would add significant complexity to maintaining spatial coherence during editing.
- Physical Interaction Complexity: While the framework outputs where objects should go, the actual how of physically moving them (e.g., grasp planning, collision avoidance during movement, force control) is outside the scope of this paper. It's a planning layer, not an execution layer for complex robotics.
- Scaling to Extreme Complexity: While it performs well on benchmarks, scaling to highly cluttered environments with thousands of unique objects and intricate spatial constraints might still pose challenges for the reasoning engine and
scene graphrepresentation.
Can a Hobbyist Replicate This?
Replicating this exact research for a hobbyist would be challenging. The model training involves large Vision-Language Models and specialized reward functions, requiring substantial computational resources. The scene-graph representation itself needs robust parsing and generation tools. However, the concept of structured reasoning is highly applicable. Hobbyists could leverage existing open-source scene graph libraries and integrate smaller, fine-tuned language models (like Llama.cpp variants) to handle more constrained spatial editing tasks within a simulated or highly controlled environment. Access to 3D simulation tools (like Gazebo or Unity with ROS) and basic robotic arms (e.g., UFACTORY Lite 6) would be essential for experimentation with the physical manipulation aspect. The core Structured Reasoning approach could inspire simpler, rule-based systems for specific tasks.
Building on Foundational Spatial Intelligence
This work builds on a growing body of research exploring how AI understands and interacts with the physical world. For a drone to effectively "rearrange the tools," it first needs to understand how objects relate spatially. Papers like "The Dual Mechanisms of Spatial Reasoning in Vision-Language Models" by Cui et al. delve into the foundational understanding of how VLMs compute these spatial relations, providing the underlying cognitive framework for 3D-Layout-R1's capabilities. Furthermore, for a drone to move and act upon these spatial instructions, a unified understanding of text, vision, and motion is critical. "UniMotion: A Unified Framework for Motion-Text-Vision Understanding and Generation" by Wang et al. presents a relevant approach for integrating these modalities, though focused on human motion, its principles apply to robotic action. Finally, the precise execution of these spatial edits demands accurate perception of movement. "GenOpticalFlow: A Generative Approach to Unsupervised Optical Flow Learning" by Luo et al. highlights the importance of optical flow for a drone's precise navigation and interaction, ensuring high-fidelity object manipulation and collision avoidance during the execution of spatial editing tasks.
The Future of Interactive Drones
3D-Layout-R1 is a strong step towards drones that don't just follow pre-programmed paths but intelligently interpret and execute complex spatial rearrangement tasks from human language. This isn't just about moving objects; it's about giving drones a deeper, more actionable understanding of their 3D world. What will you tell your drone to reorganize first?
Paper Details
Title: 3D-Layout-R1: Structured Reasoning for Language-Instructed Spatial Editing Authors: Haoyu Zhen, Xiaolong Li, Yilin Zhao, Han Zhang, Sifei Liu, Kaichun Mo, Chuang Gan, Subhashree Radhakrishnan arXiv: 2603.22279 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.