Psi-Zero: The Universal Brain That Could Arm Your Drone with Hands
A new open foundation model, $Ψ_0$, dramatically improves robot loco-manipulation by strategically decoupling human and robot data, paving the way for drones that can perform complex physical tasks.
From Flight to Fine Motor Skills: A New Era for Drones
We talk a lot about autonomous flight, navigation, and even drone swarms. But what about drones that don't just observe or deliver, but actively do? Imagine a drone that could pick up a dropped tool, re-route a loose cable, or even assemble a complex structure mid-air. That future hinges on giving drones the same kind of adaptable, dexterous physical intelligence we're seeing in advanced humanoid robots. A new paper introduces $Ψ_0$, an open foundation model that’s making that universal physical intelligence a tangible reality, and it has significant implications for how we'll build and program drones next.
The Data Deluge Problem
Teaching robots to perform complex loco-manipulation—tasks involving both movement and fine motor skills—has always been a monumental challenge. Current approaches often try to throw massive amounts of diverse human and robot data into a single training pot. The idea is that more data equals better learning.
However, this strategy hits a wall because humans and humanoid robots have fundamental kinematic and motion differences. What works for a human hand doesn't directly translate to a robot's gripper. This disparity means that simply scaling up data, especially noisy internet videos or heterogeneous robot datasets, leads to data inefficiency and unsatisfactory model performance. You end up with models that are data-hungry but still struggle with precision and generalization, making them too costly and unreliable for real-world deployment on mobile platforms like drones.
A Smarter Path to Robot Intelligence
$Ψ_0$ tackles this problem head-on by decoupling the learning process. Instead of one giant, inefficient training phase, it uses a staged paradigm with distinct learning objectives. This approach maximizes the utility of different data sources.
First, a Vision-Language Model (VLM) backbone is pre-trained on large-scale egocentric human videos. Think first-person footage of someone performing tasks. This stage helps the model acquire generalizable visual-action representations—it learns what to look for and what kind of actions are relevant in a task space.
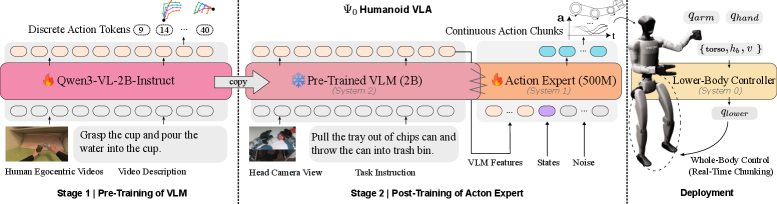 Figure 2: Model Training and Deployment: First, we pre-train the VLM on the EgoDex [20] dataset to autoregressively predict the next-action tokens in the task space. Then, we post-train the flow-based action expert using robotic data to predict action chunks in the joint space. Finally, we implement a real-time chunking mechanism that leverages the lower-body controller to achieve smooth whole-body control.
Figure 2: Model Training and Deployment: First, we pre-train the VLM on the EgoDex [20] dataset to autoregressively predict the next-action tokens in the task space. Then, we post-train the flow-based action expert using robotic data to predict action chunks in the joint space. Finally, we implement a real-time chunking mechanism that leverages the lower-body controller to achieve smooth whole-body control.
Then comes the crucial second stage: a flow-based action expert is post-trained using high-quality humanoid robot data. This step focuses on translating the abstract visual-action understanding into precise robot joint control. It's about teaching the robot how to physically execute the actions it conceptually understands.
The research also highlights a critical data recipe: pre-training on high-quality egocentric human manipulation data, followed by post-training on domain-specific real-world humanoid trajectories. This focused approach, rather than scaling with noisy, diverse data, proved far more effective. A key component for smooth execution is the Real-Time Chunking (RTC) mechanism, which mitigates control jitter by ensuring smooth transitions between consecutive action segments.
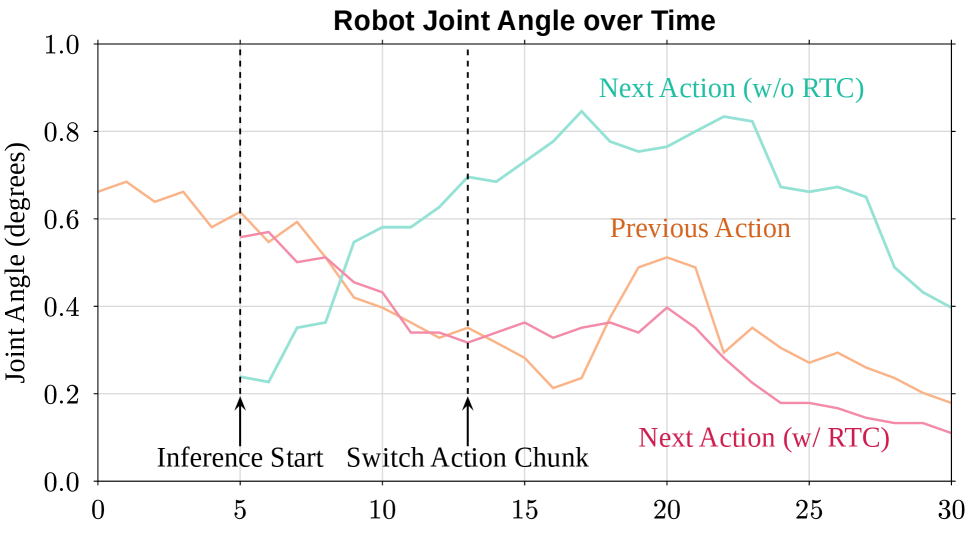 Figure 4: Real-Time Chunking: Given that the previous action is being executed (yellow line), the next action can diverge significantly (cyan line) without RTC, which leads to control jitter. With RTC (red line), the divergence between two consecutive actions is strongly suppressed, resulting in smoother and more stable behavior.
Figure 4: Real-Time Chunking: Given that the previous action is being executed (yellow line), the next action can diverge significantly (cyan line) without RTC, which leads to control jitter. With RTC (red line), the divergence between two consecutive actions is strongly suppressed, resulting in smoother and more stable behavior.
This system involves a client-server architecture where the client handles observation collection and action execution, while the server manages control and inference asynchronously. This design is critical for real-time performance.
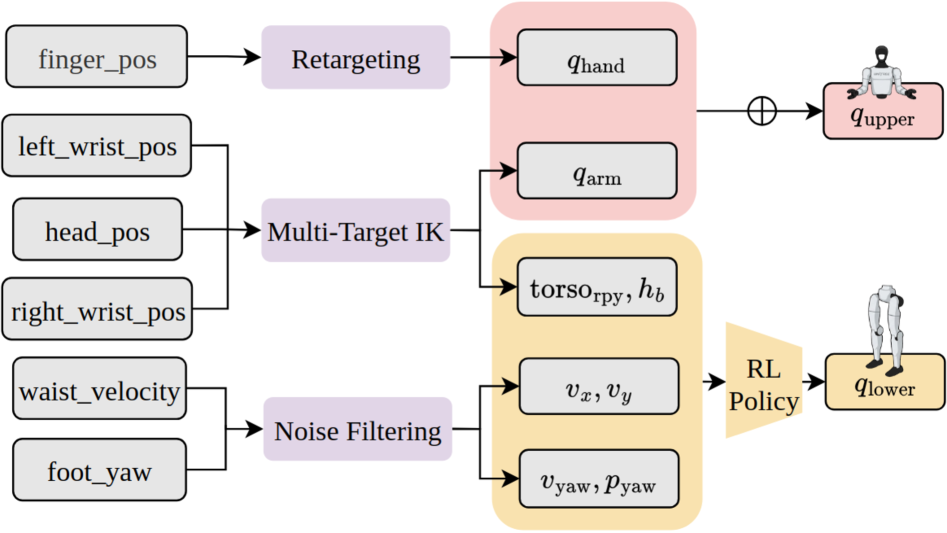 Figure 9: Real-Time Action Chunking System Design. The system consists of a client (observation collection and action execution) and a server (control and inference). The Control Loop (30Hz) coordinates observation updates and action dispatch, while the Inference Loop runs asynchronously to compute the next action chunk when t≥smint≥s_{ ext{min}}, enabling seamless chunk transitions without inference-induced interruptions.
Figure 9: Real-Time Action Chunking System Design. The system consists of a client (observation collection and action execution) and a server (control and inference). The Control Loop (30Hz) coordinates observation updates and action dispatch, while the Inference Loop runs asynchronously to compute the next action chunk when t≥smint≥s_{ ext{min}}, enabling seamless chunk transitions without inference-induced interruptions.
Performance that Matters
$Ψ_0$'s results are impressive, especially considering the data efficiency. Using only about 800 hours of human video data and a mere 30 hours of real-world robot data, it achieved superior performance. This contrasts sharply with baselines that often required more than 10 times the data volume.
- Overall Success Rate: $Ψ_0$ outperformed baselines by over 40% across multiple challenging loco-manipulation tasks.
- Data Efficiency: Achieved state-of-the-art results with significantly less robot-specific training data (30 hours vs. hundreds).
- Diverse Tasks: Evaluated on eight long-horizon, dexterous tasks involving manipulation, whole-body motion, and locomotion, demonstrating broad applicability.
 Figure 6: Real-World Task Setup: We evaluate Ψ0\Psi_{0} on eight diverse long-horizon dexterous loco-manipulation tasks involving manipulation, whole-body motion, and locomotion. The task instruction is overlayed on the task images and each sub-task is denoted with marker for better visualization. Our policy rollout videos are included in the Supplementary Materials.
Figure 6: Real-World Task Setup: We evaluate Ψ0\Psi_{0} on eight diverse long-horizon dexterous loco-manipulation tasks involving manipulation, whole-body motion, and locomotion. The task instruction is overlayed on the task images and each sub-task is denoted with marker for better visualization. Our policy rollout videos are included in the Supplementary Materials.
Why This Matters for Drones
This isn't just about humanoid robots; it's about a universal 'brain' for physical interaction that could be adapted for any multi-limbed or articulated robot, including drones. For drone hobbyists and builders, this research paves the way for:
- Advanced Inspection & Repair: Drones equipped with manipulators could not only identify issues but also perform on-site repairs—tightening bolts, cutting wires, or re-seating components on infrastructure like wind turbines or power lines.
- Autonomous Assembly: Imagine drone swarms not just lifting components, but precisely assembling structures in environments too dangerous or inaccessible for humans.
- Search & Rescue: Drones could clear debris, open doors, or provide first aid in disaster zones, using their manipulation skills to navigate and interact with complex environments.
- Logistics & Inventory: Mini drones could potentially perform highly dexterous tasks within warehouses, like arranging shelves, picking specific items, or even performing light maintenance on equipment.
The core takeaway is that a foundation model like $Ψ_0$ provides a unified learning framework. Instead of programming each task, a drone could learn to perform a vast array of physical interactions by observing human actions and then refining those skills with its own specific hardware. This is how you get closer to the 'I could build that' future of truly versatile drone autonomy.
Real-World Hurdles and Unanswered Questions
While $Ψ_0$ marks a significant step, real-world deployment on drones faces several challenges:
- Computational Overhead: Running a complex foundation model in real-time on a drone's constrained edge hardware will require substantial optimization. The current client-server architecture implies a powerful server, which isn't always feasible for untethered drones.
- Hardware Integration: Adapting this model from humanoids to multi-rotor drones with robotic arms will require careful kinematic mapping and inverse kinematics solutions specific to drone manipulators.
- Dynamic Environments: The tasks demonstrated are largely in controlled lab settings. Real-world drone operation involves unpredictable wind, lighting changes, and moving objects, demanding even greater robustness.
- Safety & Reliability: For any physical interaction, safety is paramount. Ensuring the drone's manipulators operate reliably and predictably, especially around humans or critical infrastructure, is a major engineering task.
- Data Generalization: While $Ψ_0$ is data-efficient, the quality of the human egocentric data and robot trajectories remains crucial. Sourcing and annotating such high-quality data for specific drone applications could still be a bottleneck.
Building Tomorrow's Autonomous Systems Today
Crucially, the authors plan to open-source the entire $Ψ_0$ ecosystem, including the data processing and training pipeline, the humanoid foundation model itself, and a real-time action inference engine. This is a massive win for the robotics community and especially for ambitious drone builders.
While training a full foundation model from scratch requires significant compute and data, the open-sourced model and tools mean you could potentially fine-tune it for specific drone manipulator tasks. The framework provides a solid starting point for experimentation, allowing hobbyists and researchers to adapt the learned representations to novel drone hardware, provided they can generate or access sufficient high-quality demonstration data for their specific robot arm.
This open-source approach aligns perfectly with the needs of the community, enabling rapid iteration and customization. The ability to manage computational resources, as explored in related work like "One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers", will be critical for running such models efficiently on drone hardware.
This work also builds on foundational concepts like robust visual reasoning, which is essential for complex manipulation. "MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning" highlights the need for reliable decision-making in visual workflows, a capability $Ψ_0$ would leverage for multi-step tasks. Similarly, "EndoCoT: Scaling Endogenous Chain-of-Thought Reasoning in Diffusion Models" points towards breaking down complex problems into logical sequences, allowing a drone to tackle intricate assembly or repair operations. And for precise interaction, accurate 3D perception is non-negotiable; "DVD: Deterministic Video Depth Estimation with Generative Priors" offers a robust method for drones to achieve this critical spatial awareness.
This isn't just a step; it's a leap towards drones that are not just intelligent in the air, but truly capable of intelligent physical interaction with the world.
Paper Details
Title: $Ψ_0$: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation Authors: Songlin Wei, Hongyi Jing, Boqian Li, Zhenyu Zhao, Jiageng Mao, Zhenhao Ni, Sicheng He, Jie Liu, Xiawei Liu, Kaidi Kang, Sheng Zang, Weiduo Yuan, Marco Pavone, Di Huang, Yue Wang Published: March 2026 (arXiv preprint) arXiv: 2603.12263 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.