Predicting the Future: How DynVLA Gives Drones 'Foresight'
A new AI model, DynVLA, learns to predict future world dynamics compactly before taking action, enabling more informed and physically grounded decision-making for autonomous systems like drones.
TL;DR: DynVLA is a novel Vision-Language-Action (VLA) model that predicts future world dynamics in a compact, tokenized form before generating actions. This 'Dynamics CoT' approach allows autonomous systems to make more informed, physically grounded decisions efficiently, outperforming current textual or visual reasoning methods.
Autonomous drones constantly make decisions based on immediate observations. But what if a drone could anticipate events five seconds into the future? What if it could predict a pedestrian's turn, a gust of wind shifting a branch, or a vehicle braking ahead, all before they occur? This capability is at the heart of DynVLA, a new research paper introducing a powerful approach to giving autonomous agents, including future drones, a crucial form of 'future sight' by learning to predict complex world dynamics.
The Challenge: Reactive Drones and Costly Predictions
Currently, many advanced autonomous systems, whether driving cars or navigating drones, often rely on reactive decision-making or computationally heavy predictive methods. Traditional 'Chain-of-Thought' (CoT) models in Vision-Language-Action (VLA) systems generally fall into two categories: Textual CoT and Visual CoT. Textual CoT attempts to reason about the world using language, which struggles with the fine-grained spatiotemporal understanding needed for dynamic environments and introduces significant inference latency due to verbose reasoning traces. Visual CoT, on the other hand, tries to predict future frames or dense pixel-level changes. While visually rich, this approach introduces substantial redundancy and heavy computational overhead, making it impractical for resource-constrained platforms like many drones with limited onboard processing power and battery life. These limitations mean drones cannot always react optimally or plan far enough ahead in complex, rapidly changing environments.
DynVLA's Solution: Compact Dynamics for Proactive Decisions
DynVLA tackles this by introducing a new Dynamics CoT paradigm. Instead of generating long text descriptions or dense pixel predictions, DynVLA first forecasts compact world dynamics before generating any action. DynVLA achieves this through a Dynamics Tokenizer which compresses the future evolution of the environment into a small, discrete set of 'dynamics tokens.' Think of it as distilling the essence of future movement and change into a concise digital fingerprint. The model intelligently decouples ego-centric dynamics (how the drone itself will move) from environment-centric dynamics (how other objects and the world around it will change). This separation is crucial for accurately modeling the rich, interaction-intensive dynamics of real-world scenarios, preventing issues like 'codebook collapse' (Figure 5) where the model fails to learn distinct representations.
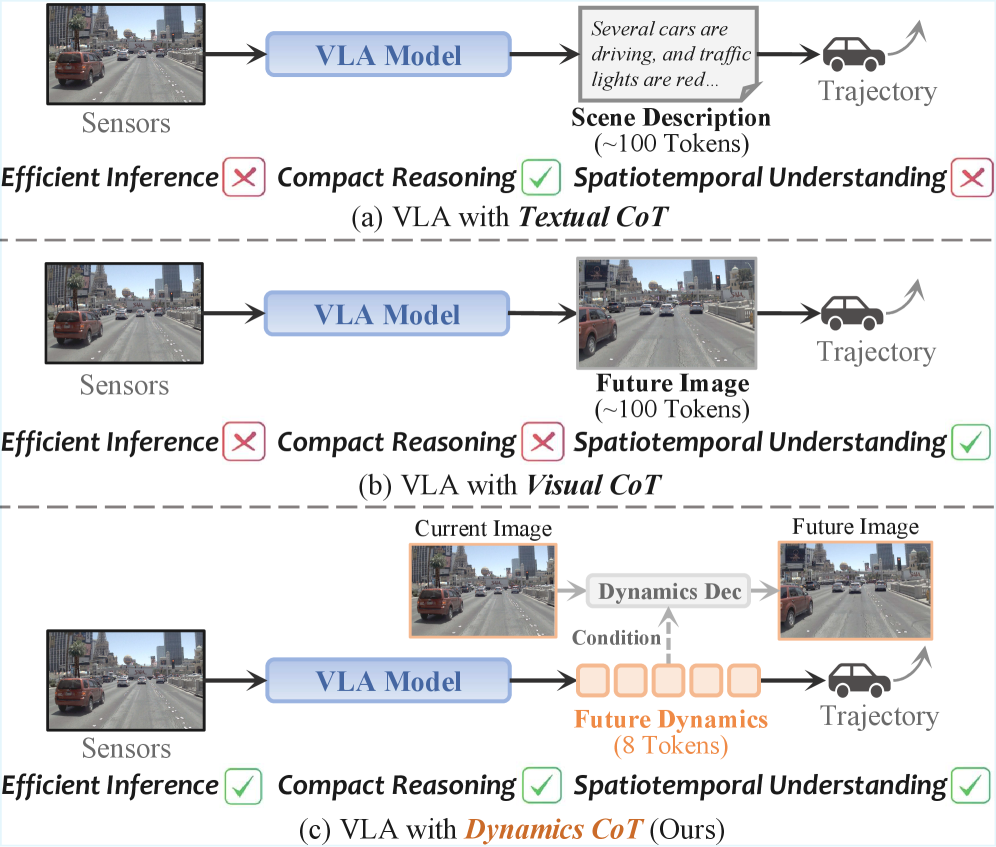 Figure 1: Traditional Textual CoT (a) is slow and lacks detail, while Visual CoT (b) is computationally heavy. Dynamics CoT (c) offers a compact, efficient, and accurate alternative by predicting future dynamics as discrete tokens.
Figure 1: Traditional Textual CoT (a) is slow and lacks detail, while Visual CoT (b) is computationally heavy. Dynamics CoT (c) offers a compact, efficient, and accurate alternative by predicting future dynamics as discrete tokens.
Under the Hood: How DynVLA Learns to See the Future
At a high level, the system works by taking adjacent image observations. A dynamics encoder then extracts both ego-centric and environment-centric dynamics. These are then discretized into VQ codebooks – essentially a learned dictionary of possible dynamics. During training, the ground-truth ego action regularizes the ego-centric dynamics, and the combined dynamics are then decoded to reconstruct future images and BEV (Bird's Eye View) maps, providing a powerful supervisory signal. DynVLA's training proceeds in stages: first, the Dynamics Tokenizer learns to reconstruct future states, producing those discrete dynamics tokens. Then, Supervised Fine-Tuning (SFT) trains the model to generate these dynamics tokens before action tokens. Finally, Reinforcement Fine-Tuning (RFT) optimizes the policy with trajectory-level rewards.
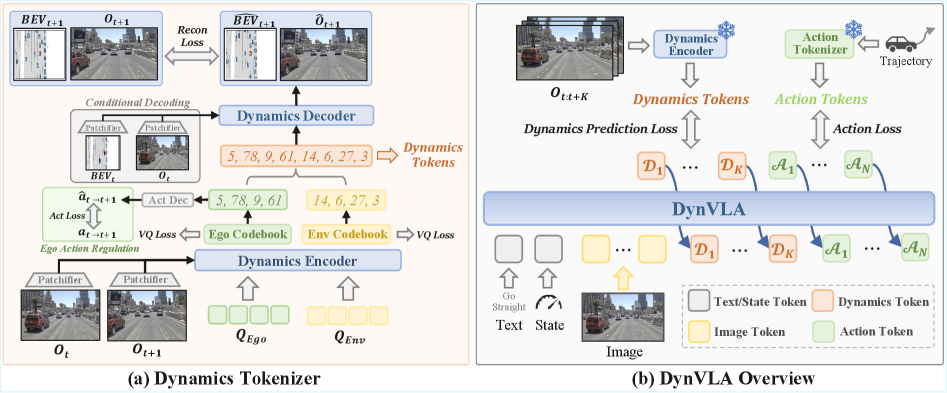 Figure 2: DynVLA extracts ego-centric and environment-centric dynamics from image observations, discretizes them into tokens, and uses these to predict future states before generating actions.
Figure 2: DynVLA extracts ego-centric and environment-centric dynamics from image observations, discretizes them into tokens, and uses these to predict future states before generating actions.
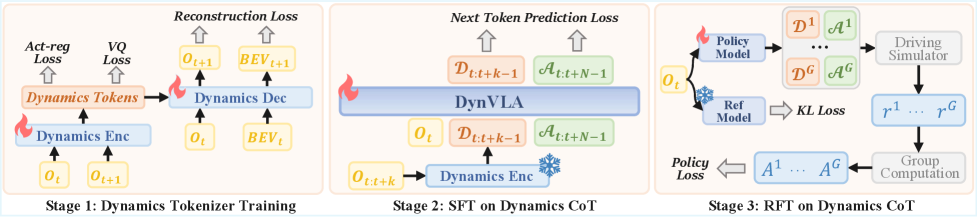 Figure 3: DynVLA's training pipeline involves learning a Dynamics Tokenizer, then SFT and RFT to generate dynamics tokens before action tokens.
Figure 3: DynVLA's training pipeline involves learning a Dynamics Tokenizer, then SFT and RFT to generate dynamics tokens before action tokens.
Real-World Impact: Smarter, Faster Decisions
This approach yields significant improvements. DynVLA consistently outperforms both Textual CoT and Visual CoT methods across various benchmarks including NAVSIM, Bench2Drive, and a large-scale in-house dataset. The core benefit is improved decision quality achieved through more informed and foresighted planning, all while maintaining latency-efficient inference. The model's ability to compress complex future evolution into a small set of tokens means less data to process and faster decision cycles. For instance, Figure 6 visually demonstrates how Dynamics CoT leads to safer and more feasible planning in challenging scenarios by providing intent-aware and constraint-compliant future dynamics, compared to direct action prediction. The decoded future images and BEV maps (Figure 7) show a faithful capture of both ego motion and surrounding agent dynamics, validating the accuracy of the dynamics tokens.
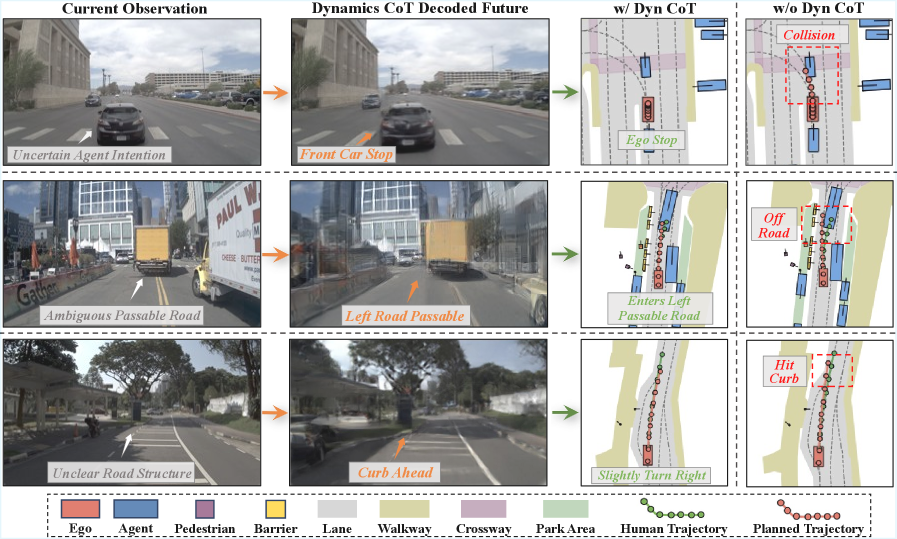 Figure 6: Dynamics CoT allows for more foresighted and safer planning by explicitly reasoning about future dynamics, preventing potential collisions.
Figure 6: Dynamics CoT allows for more foresighted and safer planning by explicitly reasoning about future dynamics, preventing potential collisions.
 Figure 7: The DynVLA Dynamics Tokenizer accurately decodes future images and BEV maps, demonstrating its ability to capture both ego-motion and surrounding object dynamics.
Figure 7: The DynVLA Dynamics Tokenizer accurately decodes future images and BEV maps, demonstrating its ability to capture both ego-motion and surrounding object dynamics.
Drones with Foresight: New Possibilities
For drone operations, this represents a significant leap forward. Consider a search and rescue drone that not only identifies a person but also predicts their movement path or the trajectory of falling debris. An inspection drone could anticipate subtle structural shifts in a bridge or predict the behavior of wildlife near a power line. Delivery drones in urban environments could more reliably predict pedestrian and vehicle movements, enabling safer and more efficient routes. By predicting the world, drones can engage in genuinely proactive rather than reactive navigation, leading to safer operations, more complex mission capabilities, and potentially longer flight times through optimized energy expenditure from better planning. The transferability of learned dynamics (Figure 4), where dynamics tokens extracted from one scenario can be injected into a new scene to accurately decode future states, also suggests strong generalization capabilities, which is vital for real-world drone deployment across varied environments.
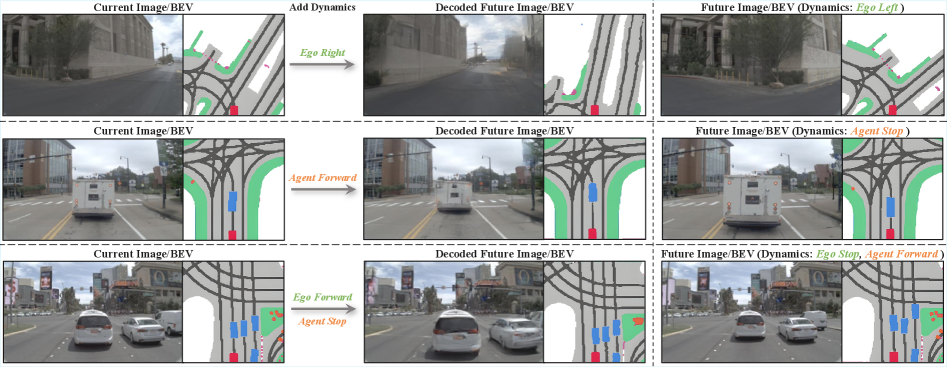 Figure 4: Dynamics tokens learned in one scenario can be transferred to a new scene, demonstrating the model's ability to generalize learned dynamics across different environments.
Figure 4: Dynamics tokens learned in one scenario can be transferred to a new scene, demonstrating the model's ability to generalize learned dynamics across different environments.
The Road Ahead: Current Limitations and Future Challenges
DynVLA is not a silver bullet. The paper acknowledges several limitations. The model can make incorrect inferences about surrounding vehicles’ intentions, misidentify drivable areas during large turning maneuvers, and struggle with ambiguous dynamics reasoning when visual observations are degraded (e.g., in poor weather or low light, as shown in Figure 10). While the paper focuses on autonomous driving, transferring these dynamics models to drone flight introduces additional complexity with 3D dynamics, aerodynamics, and potentially more complex interactions with the environment (like wind). The underlying reliance on visual data means performance will be sensitive to sensor quality and environmental conditions. Though inference is efficient, the computational cost of training such a comprehensive VLA model and its Dynamics Tokenizer is substantial, requiring significant data and powerful hardware.
Beyond the Lab: Accessibility for Builders
Replicating DynVLA from scratch is far beyond the scope of a typical hobbyist. This is a large-scale research effort involving a complex VLA model, extensive datasets, and significant computational resources for training. While the principles are fascinating, building a custom Dynamics CoT system would require expertise in deep learning, computer vision, and access to powerful GPUs. However, the concepts are highly relevant. As these models mature and potentially become available as pre-trained modules or open-source frameworks, smaller, specialized versions could emerge that are more accessible for advanced builders working on custom drone projects.
Broader Context: How DynVLA Fits In
DynVLA's work complements other cutting-edge research. For instance, while DynVLA enables drones to predict world dynamics for better action planning, PPGuide: Steering Diffusion Policies with Performance Predictive Guidance introduces a mechanism to predict the performance of those planned actions. Together, these could form a system where drones not only predict future states but also ensure their actions within that predicted world are robust and successful. Furthermore, DynVLA is a Vision-Language Model at its core, relying on accurate environmental understanding. GroundCount: Grounding Vision-Language Models with Object Detection for Mitigating Counting Hallucinations directly addresses a common VLM limitation. For DynVLA to accurately predict world dynamics, it first needs to correctly perceive the current world, making improvements to VLM accuracy critically important. Looking beyond navigation, a drone empowered by DynVLA's predictive capabilities could execute highly sophisticated inspection missions using advanced sensing. Neural Field Thermal Tomography: A Differentiable Physics Framework for Non-Destructive Evaluation offers a novel method for 3D reconstruction of material properties. An intelligently navigating drone, aware of future dynamics, could precisely position itself to conduct such non-destructive evaluations, demonstrating a powerful application of advanced autonomy.
The ability to predict the future, even a few seconds ahead, fundamentally changes the decision-making paradigm for autonomous drones. This is not just about faster reactions; it is about strategic, informed planning that could unlock entirely new levels of drone autonomy and application.
Paper Details
Title: DynVLA: Learning World Dynamics for Action Reasoning in Autonomous Driving Authors: Shuyao Shang, Bing Zhan, Yunfei Yan, Yuqi Wang, Yingyan Li, Yasong An, Xiaoman Wang, Jierui Liu, Lu Hou, Lue Fan, Zhaoxiang Zhang, Tieniu Tan Published: March 2026 (arXiv preprint date) arXiv: 2603.11041 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.