City-Scale Smarts: Teaching Drones to Truly Understand Urban Environments
Researchers have developed 3DCity-LLM, a framework that empowers multi-modality large language models to perceive and comprehend 3D city-scale environments. This aims to unlock unprecedented urban intelligence for drone applications.
TL;DR: Researchers built 3DCity-LLM, a framework that scales large language models to understand entire 3D cities, not just individual objects or indoor scenes. It uses a new 1.2 million sample dataset and a clever architecture to process urban data, making drones potentially much smarter about their surroundings.
Unlocking Urban Cognition from the Sky
Flying a drone through a city is one thing; having it genuinely understand the urban fabric is another. We're talking about drones that don't just see buildings and cars, but comprehend their relationships, analyze traffic flow, and even infer human activities based on complex 3D data. This isn't just about better navigation; it's about unlocking a new level of autonomous intelligence, and the 3DCity-LLM framework marks a major leap in that direction.
The City-Scale Understanding Gap
Current multi-modality large language models (MLLMs) are pretty good at understanding specific objects or navigating indoor spaces. The problem? Cities are massive, dynamic, and incredibly complex. Scaling these models to a city-wide 3D environment, where you need to process everything from individual traffic lights to entire districts and their interconnections, has been a major bottleneck.
Existing approaches fall short in integrating diverse 3D visual data with natural language queries at this scale, limiting what drones can truly "know" about their operational environment. This gap has prevented drones from moving beyond mere data collection to actual contextual urban intelligence.
How a Drone Learns a City's Language
The core idea behind 3DCity-LLM is to process city data with a "coarse-to-fine" encoding strategy. Think of it as a multi-layered brain for a drone, simultaneously looking at the big picture and the minute details.
The framework employs three parallel branches that work together:
- Target Object Encoding: This branch focuses on individual objects, understanding their properties and context.
- Inter-Object Relationship Encoding: This is crucial for urban understanding, as it analyzes how objects relate to each other in 3D space – like a building next to a park, or cars on a road.
- Global Scene Encoding: This branch provides the overarching context, understanding the city environment as a whole.
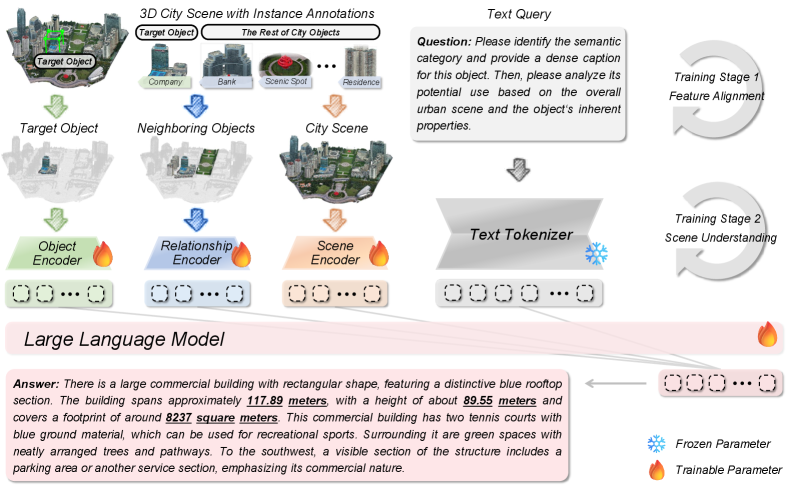 Figure 3: Model architecture of 3DCity-LLM. 3DCity-LLM receives target object, its neighboring objects, city scene and text query as multi-modality inputs, then identifies task type based on the text query and activates the corresponding feature encoding branches before producing the final answers.
Figure 3: Model architecture of 3DCity-LLM. 3DCity-LLM receives target object, its neighboring objects, city scene and text query as multi-modality inputs, then identifies task type based on the text query and activates the corresponding feature encoding branches before producing the final answers.
These branches allow the model to ingest diverse inputs, from raw 3D point clouds to semantic annotations, and process them in response to natural language queries.
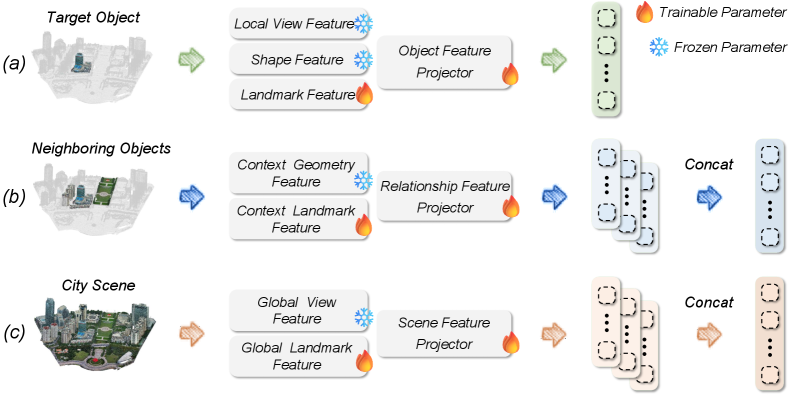 Figure 4: The coarse-to-fine feature encoding in 3DCity-LLM. (a) Object Encoding (b) Relationship Encoding (c) Scene Encoding
Figure 4: The coarse-to-fine feature encoding in 3DCity-LLM. (a) Object Encoding (b) Relationship Encoding (c) Scene Encoding
Crucially, this work relies on the new 3DCity-LLM-1.2M dataset. This isn't just a collection of images; it's a massive, quality-controlled dataset with approximately 1.2 million samples. It includes explicit 3D numerical information and diverse, user-oriented simulations across seven task categories – everything from fine-grained object analysis to complex scene planning. This rich data helps the model learn deep spatial reasoning capabilities.
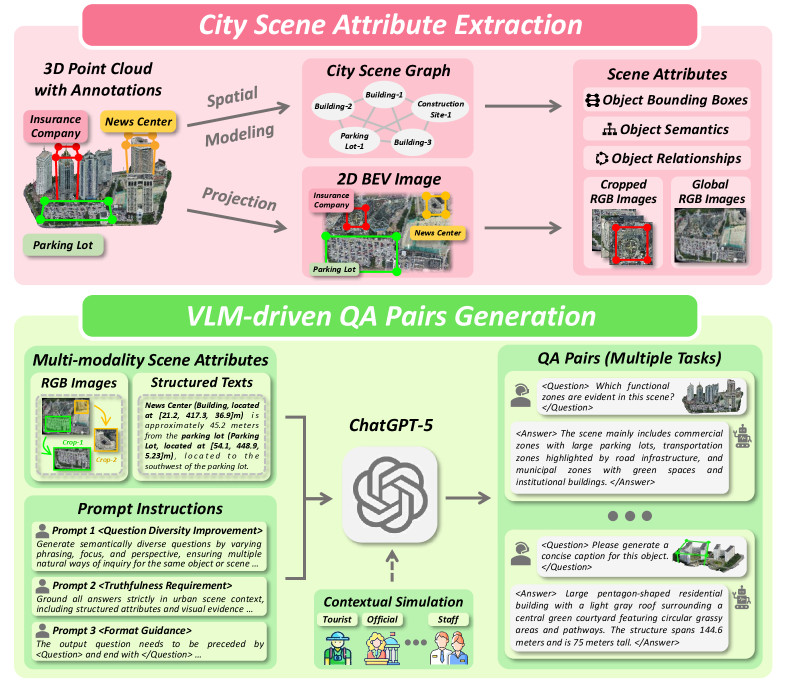 Figure 2: Automated data generation pipeline of 3DCity-LLM-1.2M dataset, leveraging instance-level masks and landmark annotations from the SensatUrban, UrbanBIS, and City-BIS datasets. We first construct city scene attributes for each environments as input for VLM, then prompt the VLM to generate diverse and high-quality QA pairs grounded in the scene with multiple instructions. In total, we built 1.2M samples spanning object caption, object localization, object analysis, relationship computation, scene caption, scene analysis and scene planning tasks.
Figure 2: Automated data generation pipeline of 3DCity-LLM-1.2M dataset, leveraging instance-level masks and landmark annotations from the SensatUrban, UrbanBIS, and City-BIS datasets. We first construct city scene attributes for each environments as input for VLM, then prompt the VLM to generate diverse and high-quality QA pairs grounded in the scene with multiple instructions. In total, we built 1.2M samples spanning object caption, object localization, object analysis, relationship computation, scene caption, scene analysis and scene planning tasks.
Concrete Gains in Urban Understanding
The team behind 3DCity-LLM reports that their framework significantly outperforms existing state-of-the-art methods across various benchmarks. While the abstract doesn't dive into specific numbers, the qualitative results shown in the paper are impressive, demonstrating the model's ability to:
- Accurately caption objects: Generating descriptive text for specific urban elements.
- Perform fine-grained object analysis: Answering detailed questions about objects within the scene.
- Precisely localize objects: Identifying and pinpointing objects in 3D space.
- Compute complex relationships: Calculating distances and orientations between multiple objects.
- Generate detailed scene captions: Describing entire urban environments.
- Conduct scene analysis: Answering high-level questions about urban dynamics and features.
- Facilitate scene planning: Providing insights for urban development or logistics based on spatial understanding.
The model also generalizes well, handling diverse queries for the same object or scene, and applying the same queries to different objects or scenes. This flexibility is key for real-world applications where variability is the norm.
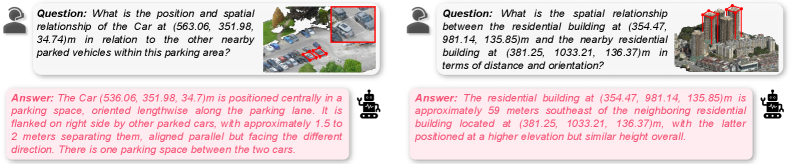 Figure 6: Qualitative results on the relationship-level tasks from 3DCity-LLM-1.2M dataset. 3DCity-LLM model can extract object information in urban scenes and calculate distance and orientation based on their coordinates.
Figure 6: Qualitative results on the relationship-level tasks from 3DCity-LLM-1.2M dataset. 3DCity-LLM model can extract object information in urban scenes and calculate distance and orientation based on their coordinates.
 Figure 7: Qualitative results on the scene-level tasks from 3DCity-LLM-1.2M dataset. (a-b) Scene Caption, (c-d) Scene Analysis, (e-f) Scene Planning
Figure 7: Qualitative results on the scene-level tasks from 3DCity-LLM-1.2M dataset. (a-b) Scene Caption, (c-d) Scene Analysis, (e-f) Scene Planning
Why This Matters for Your Drone Operations
For drone hobbyists and engineers, this isn't just academic progress; it's a blueprint for significantly smarter drones.
- Advanced Urban Mapping & Surveying: Drones could generate rich semantic maps, not just point clouds, identifying infrastructure defects, assessing green spaces, or monitoring construction progress with unprecedented detail and contextual understanding.
- Intelligent Autonomous Navigation: A drone equipped with 3DCity-LLM could navigate not just by avoiding obstacles, but by understanding traffic patterns, identifying optimal routes for package delivery, or even recognizing anomalies in pedestrian flow.
ROSintegration for such a system would unlock powerful capabilities. - Public Safety & Emergency Response: Drones could be deployed during emergencies to quickly assess damage, identify safe zones, or locate individuals by understanding the complex urban environment and responding to natural language queries from first responders.
- Smart City Applications: This framework could enable drones to act as intelligent sensors for city management, monitoring energy usage, assessing air quality, or even optimizing public transport routes by perceiving and analyzing the city in real-time.
- Environmental Monitoring: Beyond just collecting data, a drone could identify areas of concern for pollution, monitor changes in urban canopy, or track ecological impacts with a contextual understanding of the urban landscape.
The Road Ahead: Challenges and What's Missing
While 3DCity-LLM is a powerful step forward, it's essential to consider its practical limitations for drone deployment:
- Real-time Edge Deployment: Running large language models and processing high-fidelity 3D data in real-time on a drone's embedded hardware is incredibly demanding. The power, weight, and compute constraints of drones mean significant optimization would be needed before widespread adoption. The paper doesn't detail inference speeds or specific hardware requirements for deployment.
- Dynamic Environments: While the model can understand relationships, truly predicting and reacting to fast-changing, unpredictable urban dynamics (e.g., a sudden traffic jam, a crowd dispersing) remains a tough challenge. Its "understanding" is still based on learned patterns from a dataset, not true real-world common sense.
- Data Generalization: The
3DCity-LLM-1.2Mdataset is comprehensive, but real cities are infinitely varied. How well does the model generalize to unseen urban layouts, architectural styles, or highly specific local conditions? Continuously updating such a massive dataset would be a logistical challenge. - Ethical Considerations: Drones with such advanced city-scale perception raise significant privacy concerns. How would detailed 3D understanding, including inferred human activity, be managed responsibly in public spaces?
- Sensor Modality: The paper leverages existing 3D datasets. Real-world drone deployment would require robust sensor fusion from various onboard sensors (LiDAR, cameras, GPS) to feed this model, and the quality and consistency of that input data are critical.
Building Your Own City-Sensing Drone?
For ambitious hobbyists, researchers, or startups, the good news is that the source code and the substantial 3DCity-LLM-1.2M dataset are available on GitHub. This means you can get your hands dirty and experiment with the framework. However, training such a large model would require significant computational resources – likely multiple high-end NVIDIA GPUs in a lab or cloud environment. Running inference, especially if optimized, might eventually be feasible on more powerful drone platforms or through edge AI accelerators, but it's not something you'd throw on a standard Raspberry Pi-powered quadcopter tomorrow. Integrating this into a live drone system would also involve considerable SLAM, path planning, and control system engineering.
Related Efforts in Advanced Drone Perception
This work doesn't exist in a vacuum. Other researchers are tackling complementary challenges that could make 3DCity-LLM even more powerful for drone applications. For instance, "OccAny: Generalized Unconstrained Urban 3D Occupancy" provides the fundamental 3D mapping and perception capabilities that 3DCity-LLM builds upon, offering a crucial layer of environmental understanding. To make these intelligent models practical for small, power-constrained drones, efficiency is key; this is where "VISion On Request: Enhanced VLLM efficiency with sparse, dynamically selected, vision-language interactions" comes in, offering strategies to reduce the computational load of large vision-language models. Furthermore, for drones needing to identify new objects on the fly, "DetPO: In-Context Learning with Multi-Modal LLMs for Few-Shot Object Detection" would allow 3DCity-LLM-equipped drones to quickly learn and detect novel or specific items within the urban sprawl with minimal examples. Finally, "GeoSANE: Learning Geospatial Representations from Models, Not Data" points to a future where foundational geospatial knowledge could be built more efficiently, potentially streamlining the creation of the rich contextual understanding that 3DCity-LLM relies on.
The 3DCity-LLM framework brings us closer to drones that don't just see the city, but truly understand it, opening doors for new levels of urban intelligence and autonomous capabilities, potentially changing how we interact with our cities from above.
Paper Details
Title: 3DCity-LLM: Empowering Multi-modality Large Language Models for 3D City-scale Perception and Understanding Authors: Yiping Chen, Jinpeng Li, Wenyu Ke, Yang Luo, Jie Ouyang, Zhongjie He, Li Liu, Hongchao Fan, Hao Wu Published: March 2026 arXiv: 2603.23447 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.