Beyond Flight: Drones Gain Surgical Precision with 6-DOF Control
Meet GMT, a multimodal transformer empowering drones to generate incredibly precise 6-DOF object manipulation paths in complex 3D environments, surpassing human interaction benchmarks.
TL;DR: Researchers have developed GMT, a multimodal transformer that generates precise, goal-conditioned 6-DOF (six degrees of freedom) object manipulation trajectories for robots. This system integrates various 3D scene data to enable drones to perform highly accurate, collision-free object interactions, pushing beyond simple flight to complex robotic tasks.
Drones are already vital for aerial observation, delivery, and basic inspection. But what if these aerial workhorses could precisely assemble a circuit board, pick up a dropped tool with surgical accuracy, or perform delicate repairs in hazardous environments? A new paper by Zeng et al. delves into the core technology making such advanced robotic manipulation a reality, transforming drones from mere aerial platforms into true interacting agents in complex 3D spaces.
The Dexterity Dilemma: Why Precision is So Challenging
Current robotic manipulation systems, especially for mobile platforms like drones, face significant hurdles. Most rely on 2D vision or incomplete 3D representations, significantly hindering their ability to fully grasp scene geometry and execute fine-grained movements. This often results in poor spatial accuracy, collision issues, and a lack of precise orientation control—all critical for tasks requiring dexterity. Consider a drone attempting to screw in a bolt with only partial knowledge of its surroundings; it's prone to failure, damage, or simply being too slow. Existing approaches struggle with the sheer complexity of continuous 6-DOF control, often sacrificing precision for real-time operation or failing in cluttered environments.
Unlocking Dexterity: How GMT Transforms Drone Control
The core innovation here is GMT (Goal-Conditioned Multimodal Transformer), a framework designed to synthesize realistic and goal-directed 6-DOF object trajectories. The system doesn't just look at one type of data; it fuses multiple streams for a comprehensive scene understanding. It takes in 3D bounding box geometry, point cloud context, semantic object categories, and the desired end pose. This multimodal input is key to robust performance.
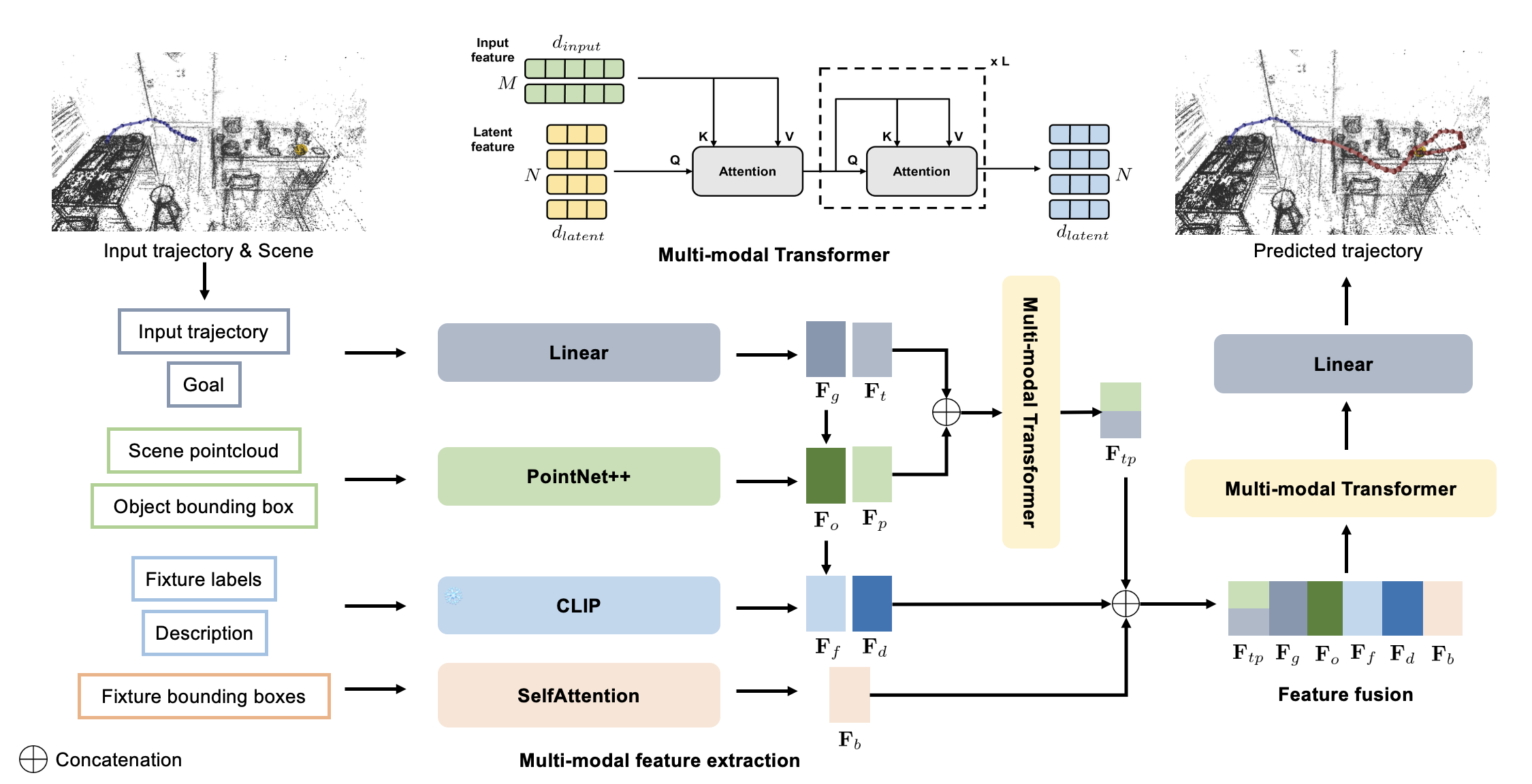 Figure 2: Pipeline overview. Given an observed trajectory and scene context, our model predicts future 6-DOF object trajectories conditioned on a specified goal state. We encode (a) trajectory dynamics, (b) local geometry propagated from the scene point cloud to the object’s bounding box, (c) semantic fixture boxes and labels, (d) natural language description of the action (e) a goal descriptor. A multimodal transformer performs hierarchical fusion that emphasizes geometric feasibility before semantic preferences. The fused latent is fed directly to the prediction head (no separate decoding stage), which we found more stable for long-horizon control.
Figure 2: Pipeline overview. Given an observed trajectory and scene context, our model predicts future 6-DOF object trajectories conditioned on a specified goal state. We encode (a) trajectory dynamics, (b) local geometry propagated from the scene point cloud to the object’s bounding box, (c) semantic fixture boxes and labels, (d) natural language description of the action (e) a goal descriptor. A multimodal transformer performs hierarchical fusion that emphasizes geometric feasibility before semantic preferences. The fused latent is fed directly to the prediction head (no separate decoding stage), which we found more stable for long-horizon control.
The model treats trajectories as continuous sequences of 6-DOF poses, meaning it understands both position (x, y, z) and orientation (roll, pitch, yaw) at every point in time. A key aspect is its tailored conditioning strategy. It prioritizes geometric feasibility—ensuring the object can actually move through the space without collisions—before considering semantic preferences, like knowing what an object is. This hierarchical fusion helps prevent physically impossible movements. Unlike some systems that separate decoding, GMT feeds the fused latent directly to the prediction head, which the authors found more stable for long-horizon control.
 Figure 3: Qualitative results on the ADT dataset. The green trajectory represents the input history across all experiments. Only our model produces trajectories that both reach the target and avoid collisions, while also achieving shorter path lengths compared to the ground-truth natural trajectories. Adaptive GIMO fails due to the absence of gaze information, whereas CHOIS accumulates errors over time, ultimately leading to failure.
Figure 3: Qualitative results on the ADT dataset. The green trajectory represents the input history across all experiments. Only our model produces trajectories that both reach the target and avoid collisions, while also achieving shorter path lengths compared to the ground-truth natural trajectories. Adaptive GIMO fails due to the absence of gaze information, whereas CHOIS accumulates errors over time, ultimately leading to failure.
The underlying data for these complex scenes often comes from careful reconstruction. For instance, in the HD-EPIC dataset, 3D bounding boxes for objects are recovered by combining input RGB frames with object masks, sparse 2D-3D correspondences from SLAM and MPS data, and monocular depth estimation. This allows accurate localization of even small objects in busy environments.
 Figure 5: 3D bounding box reconstruction in the HD-EPIC dataset. (a): input RGB frame with object mask. (b): mask filtering and sparse 2D-3D correspondences from SLAM and MPS data. (c): monocular depth estimation from UniK3D. (d): final 3D bounding box recovered after depth alignment and scaling. This pipeline enables accurate localization of small objects (e.g., bowls, cups) in cluttered scenes.
Figure 5: 3D bounding box reconstruction in the HD-EPIC dataset. (a): input RGB frame with object mask. (b): mask filtering and sparse 2D-3D correspondences from SLAM and MPS data. (c): monocular depth estimation from UniK3D. (d): final 3D bounding box recovered after depth alignment and scaling. This pipeline enables accurate localization of small objects (e.g., bowls, cups) in cluttered scenes.
Quantifiable Leaps: GMT's Performance Edge
GMT doesn't just look good on paper; it delivers quantifiable improvements. The authors tested it against state-of-the-art human motion and human-object interaction baselines, specifically CHOIS and GIMO, on synthetic and real-world benchmarks (ADT and HD-EPIC datasets).
Here's what they found:
- Superior Spatial Accuracy:
GMTsignificantly outperforms baselines in reaching target poses precisely. - Enhanced Orientation Control: It maintains better control over the object's orientation throughout the trajectory.
- Collision Avoidance: The model consistently generates collision-free paths, a critical factor for real-world robotics.
- Efficiency: Generated trajectories are often shorter and more efficient than natural human motions for the same task, implying optimized movement.
- Generalization:
GMTshows strong generalization capabilities across diverse objects and cluttered 3D environments, which is crucial for practical deployment.
In qualitative tests, baselines like Adaptive GIMO often failed due to missing information (e.g., gaze), while CHOIS accumulated errors, leading to complete task failure. GMT, however, consistently produced viable, efficient, and collision-free paths.
Real-World Impact: What This Means for Drones
This research marks a significant leap for advanced drone applications. We're talking about moving beyond camera platforms to true robotic manipulators. The implications for drone builders and engineers are substantial:
- Inspection & Repair: Drones could perform intricate inspections, manipulating tools to tighten loose screws, cut wires, or apply patches in hard-to-reach or dangerous areas (e.g., wind turbines, power lines, bridges).
- Assembly & Construction: Think small-scale automated construction or precision assembly of modular components. Drones could place tiny sensors, connect cables, or even assist in 3D printing structures with greater precision.
- Logistics & Inventory: Instead of just scanning barcodes, a drone could pick and place specific items from shelves in a warehouse, handling delicate objects with care.
- Search & Rescue (Specialized): While not for heavy lifting, a drone with this capability could delicately retrieve small, critical items from disaster zones, like evidence or personal effects, minimizing human risk.
The ability to synthesize continuous 6-DOF trajectories means a drone isn't just positioning its gripper in the right spot, but orienting it perfectly for the task, whether that's twisting, pushing, or pulling. This opens up entirely new categories of drone services and capabilities.
Navigating the Future: Limitations and Next Steps
While GMT is a significant step forward, it's not without its current limitations, some of which the authors themselves acknowledge.
- Trajectory Length: In certain failure cases (Figure 9 in the paper), the generated trajectory, despite being goal-conditioned, can be longer than the ground truth or even overshoot the destination. This indicates room for optimization in path efficiency for some scenarios.
- Redundant Motion: For small object trajectories where there isn't a significant change in position,
GMTcan sometimes introduce redundant motions (Figure 10 in the paper). This is particularly noticeable for objects interacted with for very short durations, suggesting a need for more nuanced motion planning in static or near-static conditions. - Real-world Robustness: The current system relies on accurate 3D bounding box reconstruction and scene context. Real-world drone deployment would demand highly robust
SLAMand perception systems that can handle dynamic lighting, occlusions, and varying environmental conditions without degradation in input quality. - Hardware Integration: While the paper focuses on the planning algorithm, integrating this level of precision trajectory control with actual drone hardware presents engineering challenges. It requires highly accurate actuators, low-latency sensor feedback, and robust onboard processing capabilities to execute these complex 6-DOF movements in real time. The energy consumption for such precise, sustained manipulation also needs consideration for battery-powered drones.
Can You Build It? The DIY Challenge
Replicating GMT as a hobbyist is a significant undertaking, primarily due to the computational demands and data requirements. The core of GMT is a multimodal transformer, which implies substantial GPU resources for training and potentially for inference if running locally. The datasets (ADT, HD-EPIC) are large and complex, involving detailed 3D scene reconstructions, point clouds, and semantic labels.
While the conceptual framework is clear, the implementation involves advanced machine learning, 3D vision (including SLAM and depth estimation pipelines like UniK3D), and extensive data processing. This is not an Arduino or Raspberry Pi project. However, if the authors release their code (the project page exists: https://huajian-zeng.github.io/projects/gmt/), a hobbyist with strong machine learning and robotics backgrounds, and access to powerful hardware (e.g., a high-end gaming PC or cloud GPUs), could experiment with it. Integrating it with an actual drone would require expertise in drone flight controllers, robotic arm control, and real-time sensor fusion.
Beyond GMT: A Broader Look at Robotic Intelligence
The development of GMT doesn't happen in a vacuum; it builds upon and complements several other critical areas of robotics and AI. For instance, before a drone can precisely manipulate an object, it needs to understand what that object is and where it needs to go. This is where papers like "Loc3R-VLM: Language-based Localization and 3D Reasoning with Vision-Language Models" come into play. Loc3R-VLM addresses how robots can interpret human language commands to accurately locate target objects in a 3D scene, providing the crucial "what" and "where" information that GMT can then use for trajectory planning.
Furthermore, GMT relies heavily on accurate and efficient 3D scene understanding. The paper "Feeling the Space: Egomotion-Aware Video Representation for Efficient and Accurate 3D Scene Understanding" offers a method for robust 3D perception. This is foundational; a drone needs a detailed, real-time map of its environment to plan collision-free, precise movements, and Feeling the Space contributes directly to that capability without the high computational cost of some traditional 3D representations.
Finally, as we push towards more complex robotic tasks, safety and reliability become paramount. The paper "Specification-Aware Distribution Shaping for Robotics Foundation Models" addresses this by focusing on how to ensure that robotic actions adhere to formal safety specifications. For drones performing delicate 6-DOF manipulations in real-world scenarios, guarantees on safe operation are non-negotiable, making this work a vital consideration for practical, trustworthy deployment of GMT-like systems.
This work on GMT represents a significant stride towards enabling drones to perform truly dexterous, goal-oriented manipulation, transforming them from mere aerial platforms into versatile robotic arms that can interact with our complex 3D world.
Paper Details
Title: GMT: Goal-Conditioned Multimodal Transformer for 6-DOF Object Trajectory Synthesis in 3D Scenes Authors: Huajian Zeng, Abhishek Saroha, Daniel Cremers, Xi Wang Published: March 2026 arXiv: 2603.17993 | PDF
Written by
Mini Drone Shop AISharing knowledge about drones and aerial technology.